
Всем привет. Эта глава посвящена таймерам в Node.JS. В ней я постараюсь в первую очередь рассказать о тех различиях, которые есть между таймерами в браузерах и в Node.JS. Для этого я открыл документацию
и мы видим, что несколько методов здесь очень похожи — setTimeout(), setInterval(), clearTimeout(), clearInterval(), работают практически одинаково, что в Node.JS, что в браузерах. А вот дальше уже начинаются различия. И первое отличие, мы посмотрим на примере такого вот сервера.
|
1 2 3 4 5 6 7 8 9 |
var http = require('http'); var server = new http.Server(function(req, res){ /*обработка запросов*/ }).listen(3000); setTimeout(function(){ server.close(); },2500); |
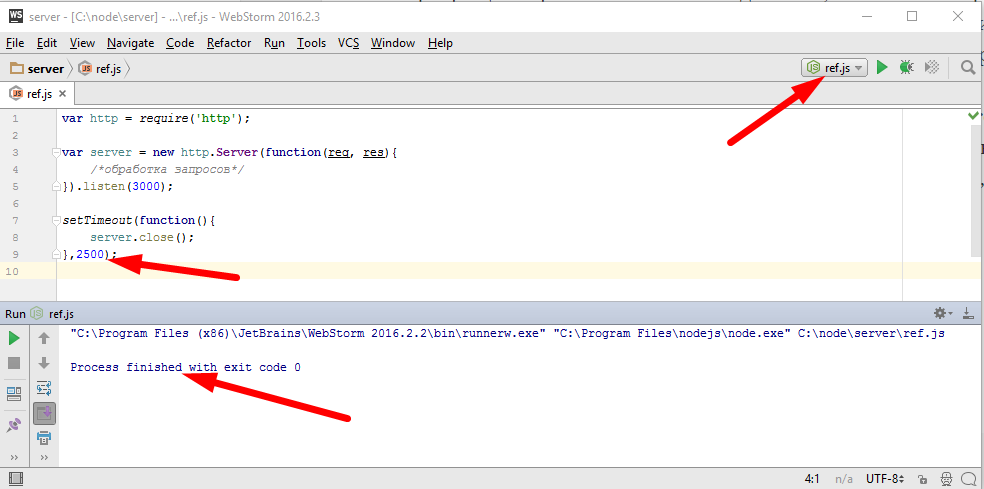
Как видим сервер этот очень простой, это можно сказать абстрактный http сервер который слушает порт 3000 и что то там делает, неважно что, с запросами. В определенный момент, например через две с половиной секунды, мы решаем прекратить функционирование этого сервера. При вызове server.close() сервер прекращает принимать новые соединения, но пока есть принятые, но не оконченные запросы они еще будут обрабатываться и только когда все соединения будут обработаны и закрыты, тогда процесс прекратится. В данном случае, я запускаю наш сервер, предварительно создав новую конфигурацию для запуска ref.js в качестве сервера, и если никаких запросов нет, то через две с половиной секунды процесс завершится. Все пока понятно, все предсказуемо.
А теперь предположим, что по мере работы этого сервера я хочу постоянно получать информацию об используемой памяти, в консоле. Что ж, нет ничего проще.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var http = require('http'); var server = new http.Server(function(req, res){ /*обработка запросов*/ }).listen(3000); setTimeout(function(){ server.close(); },2500); setInterval(function(){ console.log(process.memoryUsage()); }, 1000); |
Каждую секунду выводим, есть специальный вызов «process.memoryUsage()». Итак запускаем и смотрим,
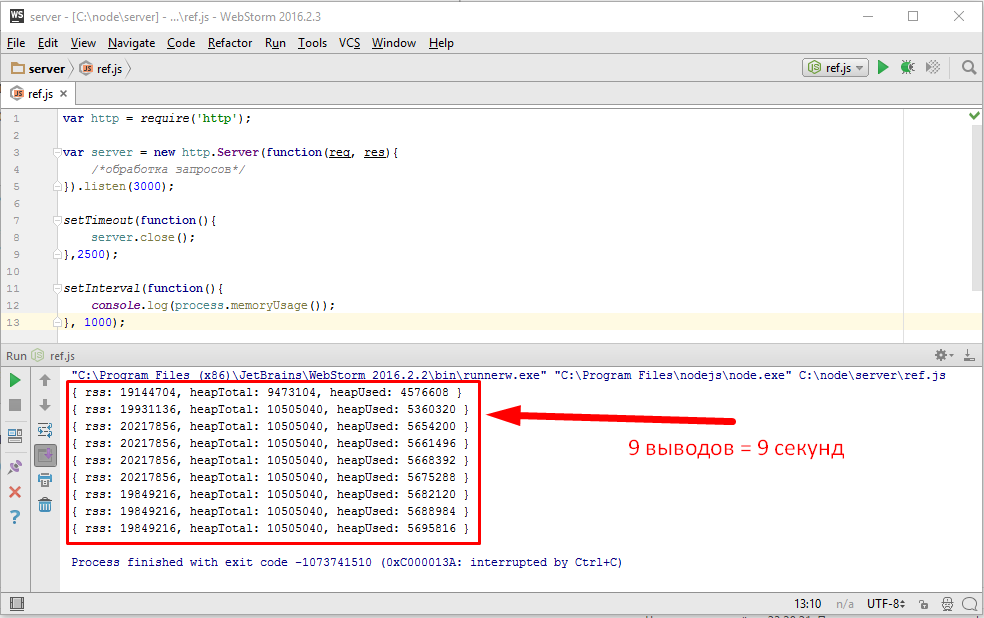
выводит информацию, сервер работает, работает, работает, пока я его не остановил вручную, но в чем же дело? Почему процесс не завершился? Ведь прошло больше чем две с половиной секунды. Конечно же во всем виноваты вот эти строки.
|
11 12 13 |
setInterval(function(){ console.log(process.memoryUsage()); }, 1000); |
Как мы помним, за таймеры, за события ввода-вывода отвечает библиотека LibUV и пока есть активный таймер LibUV не может завершить процесс. Что делать? Давайте рассмотрим несколько решений.
Первое решение, это сделать callback функции close, которая сработает когда сервер полностью закроет и обработает все соединения и в нем написать «process.exit()»
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var http = require('http'); var server = new http.Server(function(req, res){ /*обработка запросов*/ }).listen(3000); setTimeout(function(){ server.close(function(){ process.exit(); }); },2500); setInterval(function(){ console.log(process.memoryUsage()); }, 1000); |
Давайте ка попробуем
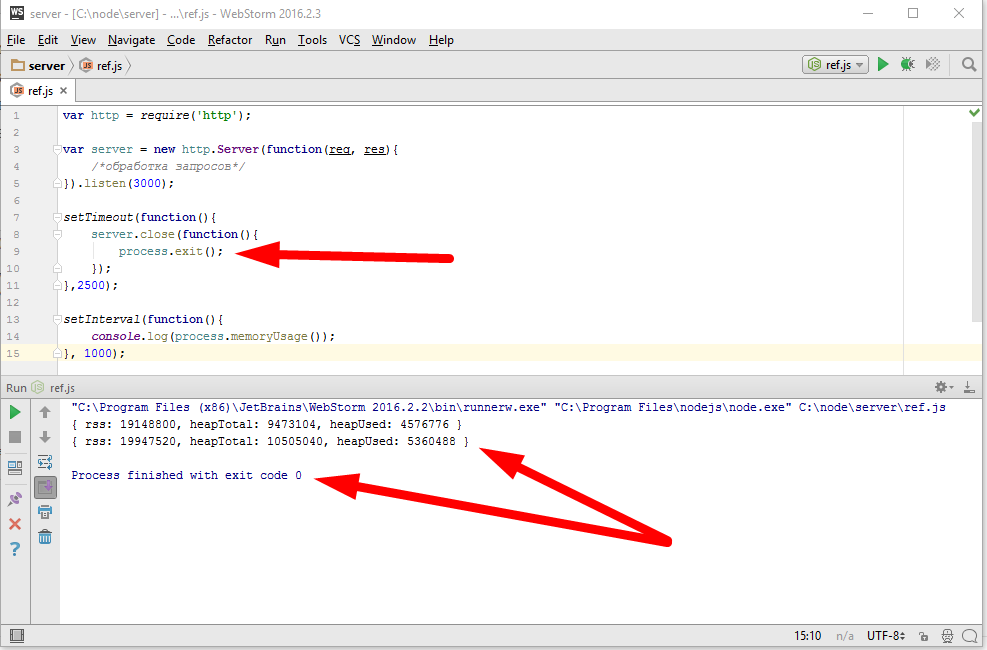
работает. С одной стороны нормально, с другой, как то это слишком уж брутально, это просто жесткое прибивание процесса. Давайте чуть чуть мягче, сделаем «clearInterval(timer)», будем очищать конкретно вот этот таймер
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var http = require('http'); var server = new http.Server(function(req, res){ /*обработка запросов*/ }).listen(3000); setTimeout(function(){ server.close(function(){ clearInterval(timer); }); },2500); var timer = setInterval(function(){ console.log(process.memoryUsage()); }, 1000); |
ну ка
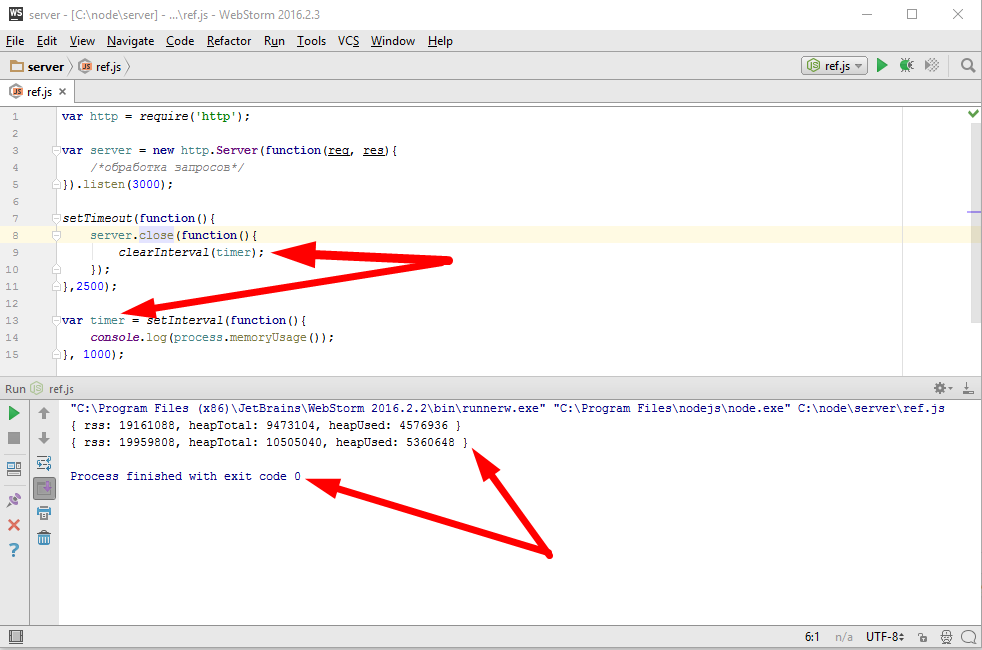
тоже все хорошо, но архитектурно и это решение не самое лучшее. Потому что, подумаем, вот сервер
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var http = require('http'); var server = new http.Server(function(req, res){ /*обработка запросов*/ }).listen(3000); setTimeout(function(){ server.close(function(){ clearInterval(timer); }); },2500); |
он может быть в одном файле, а этот setInterval(),
|
12 13 14 15 |
var timer = setInterval(function(){ console.log(process.memoryUsage()); }, 1000); |
он может быть, вообще, в другом модуле. А может быть еще и третий модуль, который тоже держит какой то свой сервер или осуществляет какие то свои операции. Что ж clearInterval(). Теперь просто остановится вывод этих сообщений, но другие операции продолжат выполняться, это чуть лучше, но все равно не так хорошо.
На самом деле, правильное решение будет в использовании специализированных возможностей Node.JS. А именно, вот здесь я оставлю close() как и было, а для setInterval(), я использую специальный метод, который называется timer.unref();
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var http = require('http'); var server = new http.Server(function(req, res){ /*обработка запросов*/ }).listen(3000); setTimeout(function(){ server.close(); },2500); var timer = setInterval(function(){ console.log(process.memoryUsage()); }, 1000); timer.unref(); |
Как видим, в отличии от браузерного JavaScript, здесь timer это объект, и метод unref() указывает LibUV, что этот timer является второстепенным, то есть его не следует учитывать при проверки внутренних watcher на завершение процесса. Давайте я запущу
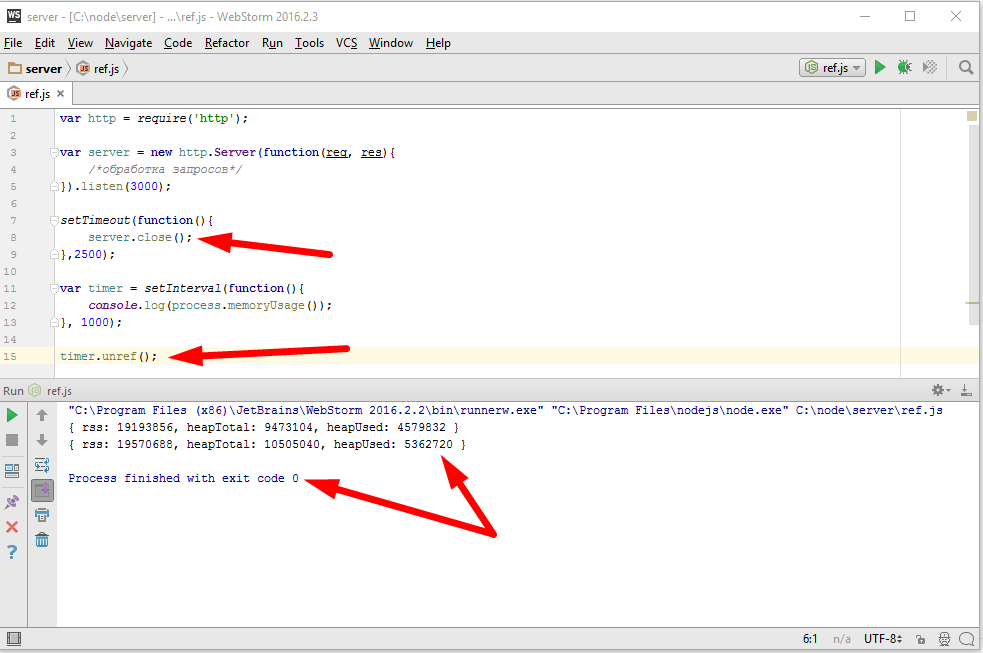
И теперь, как только серверы закончат работу, то есть, как только не останется никаких других внутренних watcher кроме вот этого timer который timer.unref(), процесс, как видим, завершился.
Есть еще метод ref(), он является противоположенным unref(), то есть если я сделал timer.unref(), потом передумал и вызвал timer.ref()то выполнение не прервется, как будто unref() не было.
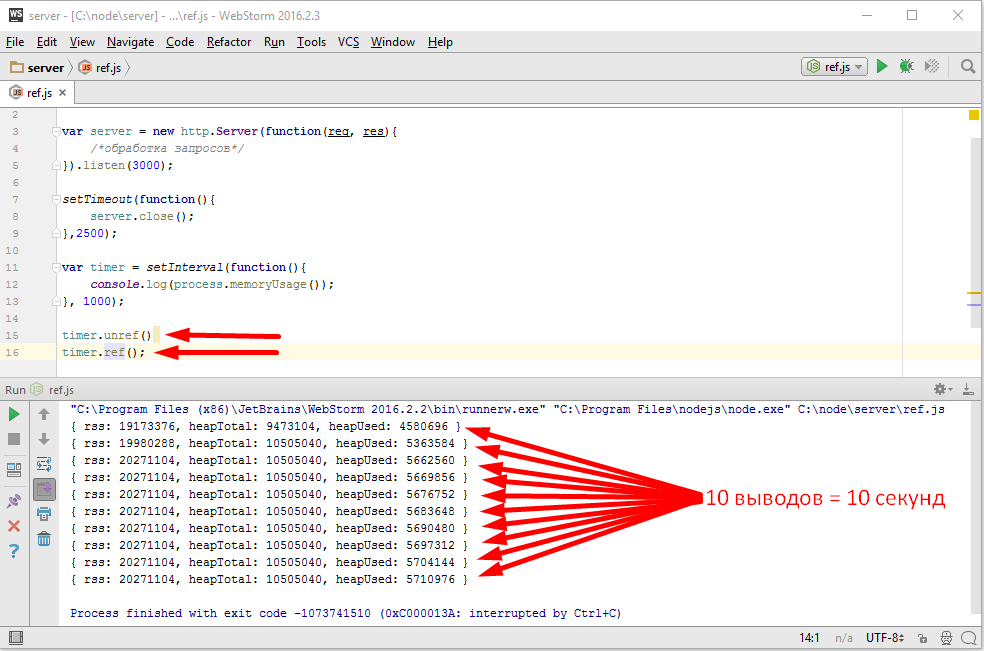
На практике ref() используется очень редко. Почему это решение лучше? Да просто потому, что здесь timer просто указывает, что он не важен, что по сути нам и требуется. Никаких побочных эффектов это не несет.
Обращаю ваше внимание, что метод unref() есть не только у timer, он есть кроме timer еще например у серверов — server.unref() или у сетевых сокетов — socket.unref(). То есть я могу сделать сетевое соединение, которое тоже не будет препятствовать завершению процесса, если оно почему то не важно.
Далее мы видим методы «setImmediate(callback[, arg][, …])» и «clearImmediate(immediateObject)»
Они тоже отличаются от браузерных. Для того чтобы лучше это понять рассмотрим следующий пример. У нас есть веб сервер и там в функции обработчике запроса понадобилось выполнить какую то операцию асинхронно. В браузере для этого обычно используется либо setTimeout(f,0), либо setImmediate или его эмуляция различными хаками, но обращаю ваше внимание в браузере немножко по другому работает событийный цикл и setImmediate браузерный, немножко не тот, мы сейчас его обсуждать не будем. Посмотрим, что в ноде происходит с setTimeout(f,0), когда сработает этот код. Можем ли мы гарантировать, что он выполнится до того как придет следующий запрос. Конечно же нет! setTimeout() выполнит его в ближайшее время, но совершенно не понятно может быть до следующего запроса, а может и после.
|
1 2 3 4 5 6 7 |
var http = require('http'); http.createServer(function(req, res){ setTimeout(function(){ //сработает до следующего запроса или после? }, 0); }).listen(1337); |
Однако, есть такие ситуации когда мы должны четко знать, что некий асинхронный код выполнится до того как в ноду придет следующий запрос или вообще любое следующие событие ввода вывода. Например потому что мы хотим повесить обработчик, скажем у нас есть req и мы хотим повесить на него, в этом setTimeout(), обработчик на следующие данные и мы должны точно знать, что этот обработчик повесится, до того как эти следующие данные будут просчитаны.
|
1 2 3 4 5 6 7 8 9 |
var http = require('http'); http.createServer(function(req, res){ setTimeout(function(){ req.on('readable', function(){ // должен сработать на ближайших данных }) }, 0); }).listen(1337); |
Для решения этой задачи в ноде есть специальный вызов — process.nextTick().
|
1 2 3 4 5 6 7 8 9 |
var http = require('http'); http.createServer(function(req, res){ process.nextTick(function(){ req.on('readable', function(){ // должен сработать на ближайших данных }) }); }).listen(1337); |
Он с одной стороны сделает выполнение функции асинхронным, то есть она выполнится после выполнения текущего JavaScript, с другой сторон он гарантирует, что выполнение произойдет, до того как придут следующие события, ввода вывода, timer и так далее.
То есть вот здесь будет это выполнение
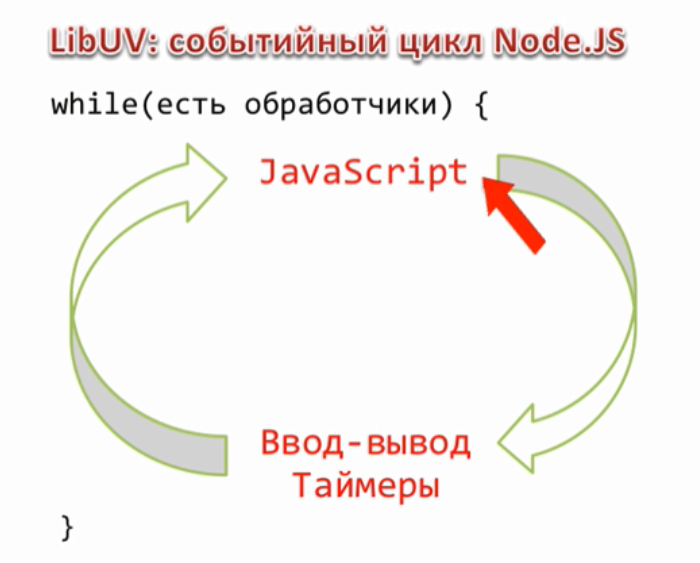
и более того, если при обработки этой функции, просто с nextTick(), выяснится, что нужно что то еще, тоже асинхронно запланировать, то вложенные, рекурсивные вызовы, просто с nextTick(), тоже добавят выполнение функции сюда же. Таким образом мы можем гарантировано повесить обработчики и они сработают до того как придут какие то еще данные.
Бывает и другая ситуация, когда мы хотим сделать функцию асинхронной, но при этом не тормозить событийный цикл. Частный пример, это когда у нас есть большая вычислительная задача, то чтобы JavaScript не блокировался здесь на долго
мы можем его попробовать разбить на части. Одну часть запустить тут же, а другую запустить так, чтоб она заработала на следующей итерации этого цикла, и другая на следующей и так далее. Для реализации этого в Node.JS есть метод — setImmediate(callback[, arg][, …]). Этот вызов как раз и планирует вызов функции так, чтоб она с одной стороны сработала как можно скорее, с другой стороны на следующей итерации цикла, после обработки текущих событий.
Рассмотрим отличия между nextTick() и setImmediate(callback[, arg][, …]) на конкретном примере.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var fs = require('fs'); fs.open(__filename, "r", function(err, file){ console.log("IO!"); }); setImmediate(function(){ console.log("immediate"); }); process.nextTick(function(){ console.log("nextTick"); }); |
Здесь я использую модуль «fs» для того чтобы открыть файл, открытие файла здесь просто как вариант операции ввода вывода. Когда файл будет открыт, то внутреннее событие LibUV которое вызовет эту функцию.
|
3 4 5 |
fs.open(__filename, "r", function(err, file){ console.log("IO!"); }); |
И Дальше я через setImmediate и process.nextTick планирую вывод сообщений. Посмотрим в каком порядке они выведутся. Создам еще одну конфигурацию сервера — io.js и запускаю
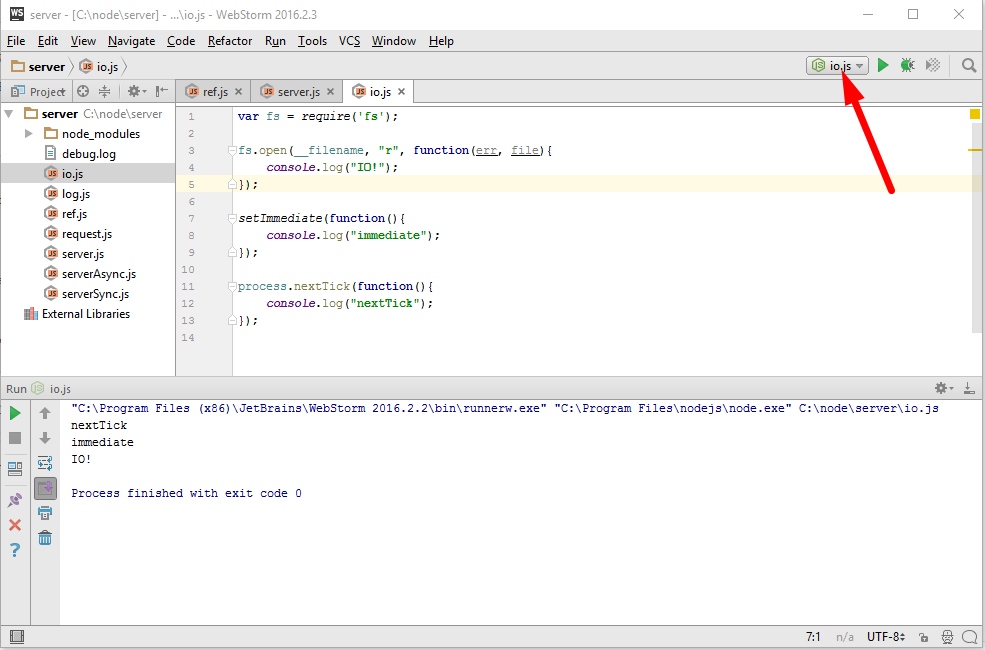
Итак, сначала конечно же вывелась nextTick, потому что nextTick планируется по окончанию текущего JavaScript, но до любых событий ввода вывода, то есть до реально открытия файла. setImmediate сработала до вводы вывода, потому что она так запланировала выполнение. А если бы я сюда добавил setTimeout(f,0), где был бы он, а вот неизвестно, может быть и здесь, а может быть и здесь гарантий нет.
Итак мы рассмотрели, чем timer в Node.JS отличаются от браузерных,
1.Это влияние на завершение процесса и методы ref(), unref().
Есть различные setTimeout(f,0) —
2. process.nextTick(f) = setTimeout(f,0) до I/O
3. setImmediate(f) = setTimeout(f,0) после I/O
В большинстве ситуаций используется process.nextTick(f), он гарантирует, что выполнение произойдет до новых событий, в частности до новых операций ввода вывода, до новых данных, как правило это наиболее безопасный вариант. Ну а setImmediate(f) планирует выполнение на следующую итерацию цикла, после обработки событий. Как правило это нужно тогда когда нам без разницы обработаются какие события или нет, то есть мы хотим что то сделать асинхронно и нам не хочется лишний раз тормозить событийный цикл, либо при разбитии сложных задач на части, чтобы одну часть обработать сейчас, другую на следующую итерацию цикла и так далее, при этом получается что задача с одной стороны постепенно делается, а с другой стороны между ее частями могут проскакивать какие то другие события, другие клиенты и серьезной задержки в обслуживании не произойдет.
Информация о порядке срабатывания событий с использованием таймера была полезной, спасибо!