
Цель этой главы, научить нас работать с бинарными данными и файловой системой. В Node.JS, для работы с файлами существует модуль «FS» и в нем есть множество функций для самых различных операций с файлами и директориями. Вот документация. Если мы приглядимся внимательно, то увидим первую особенность этого модуля, почти все функции имеют два варианта.
Первое просто имя, второе со словом Sync. Слово Sync означает синхронно.Если я например вызову fs.readFile(file[, options], callback), то он сначала прочитает файл полностью, а потом вызовет callback. А fs.readFileSync(file[, options]) затормозит выполнение процесса пока файл не будет прочитан. По этому, как правило синхронный вызов используют либо в консольных утилитах, либо на стадии инициализации сервера, когда такие тормоза допустимы. А асинхронный вызов, в тех случаях когда хочется, чтоб полноценно работал событийный цикл, то есть, чтоб Node.JS не ждал пока диск сработает, медленно и файл прочитается.
Посмотрим на реальный пример использования.
|
1 2 3 4 5 6 7 8 9 |
var fs = require('fs'); fs.readFile(__filename, function(err, data){ if(err){ console.error(err); }else{ console.log(data); } }); |
Здесь я подключаю модуль «fs» и вызываю, асинхронно, функцию readFile(…). Эта функция принимает имя файла, в данном случае «__filename» это путь к текущему файлу модуля, и получает callback, первый аргумент, как всегда, ошибка, второй данные, то есть, содержимое файла. Если бы это был синхронный вызов, то это выглядело бы так
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var fs = require('fs'); try{ var data = fs.readFileSync(__filename); }catch(e){ console.error(err); } fs.readFile(__filename, function(err, data){ if(err){ console.error(err); }else{ console.log(data); } }); |
При этом в случае ошибки было бы исключение. Но мы здесь дальше будем работать с асинхронными вызовами по этому я это удалю, а запущу наш
|
1 2 3 4 5 6 7 8 9 |
var fs = require('fs'); fs.readFile(__filename, function(err, data){ if(err){ console.error(err); }else{ console.log(data); } }); |
и вот, что я получаю в качестве вывода.
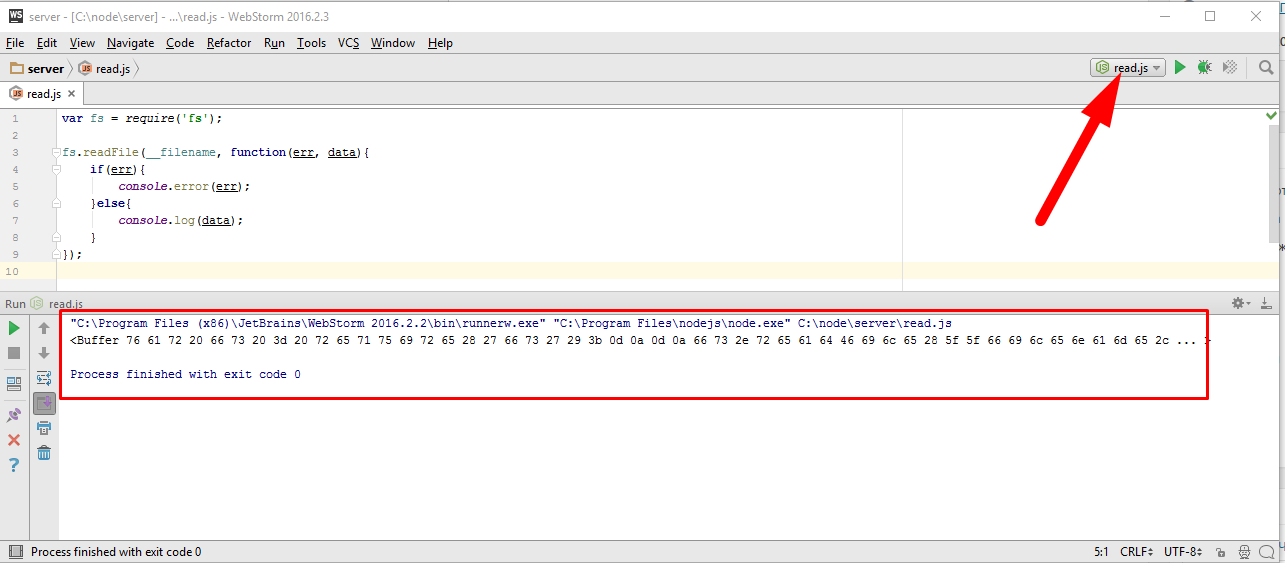
Обратите внимание, вывелось не содержимое файла в виде строки, а специальный объект буфер. Этот объект буфер является высокоэффективным средством Node.JS для работы с бинарными данными. Технически буфер, это непрерывная область памяти, которая, в данном случае, заполнена этими данными. И работа с буфером достаточно похожа на работу со строкой. То есть можно взять, например, и получить нулевой элемент.
|
1 |
data[0]; |
Можно взять и получить длину буфера
|
1 |
data.length |
Но в отличии от строк, которые в JavaScript абсолютно неизменяемы, содержимое буфера можно менять. Для этого в документации предусмотрено ряд методов, от простейшего метода buf.write(string[, offset[, length]][, encoding]) , который пишет в буфер строку, преобразуя ее в бинарный формат, учитывая данную кодировку и заканчивая различными методами которые записывают в буфер целые числа, дробные числа, числа в формате double и другие числа, учитывая внутреннее, компьютерное, двоичное представление данных форматов
В данном случае, мы бы хотели вывести содержимое файла в виде строки. По этому давайте преобразуем буфер в строку, это можно делать вызовом toString и в скобках указать кодировку, то есть таблицу, которая указывает как преобразовать байты в символы алфавита. Обычно кодировка по умолчанию — это ‘utf-8’. Если хотим так и оставить, то можно не указывать. Запускаем

Ну вот, теперь строка.
Если точно знаю, что я работаю со строками, то я могу указать кодировку прямо здесь, это будет выглядеть так
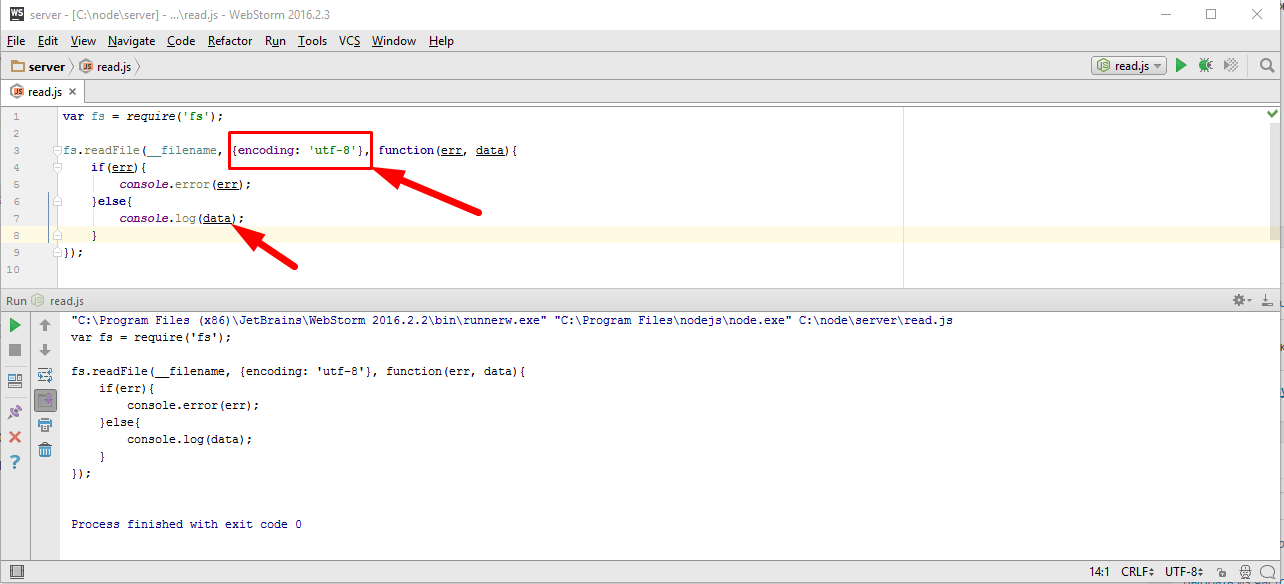
В этом случае, преобразование в строку происходит непосредственно внутри функции fs.readFile(…. ).
Ну хорошо, а теперь давайте посмотрим, что происходит если где то ошибка. Например, я считываю файл которого не существует
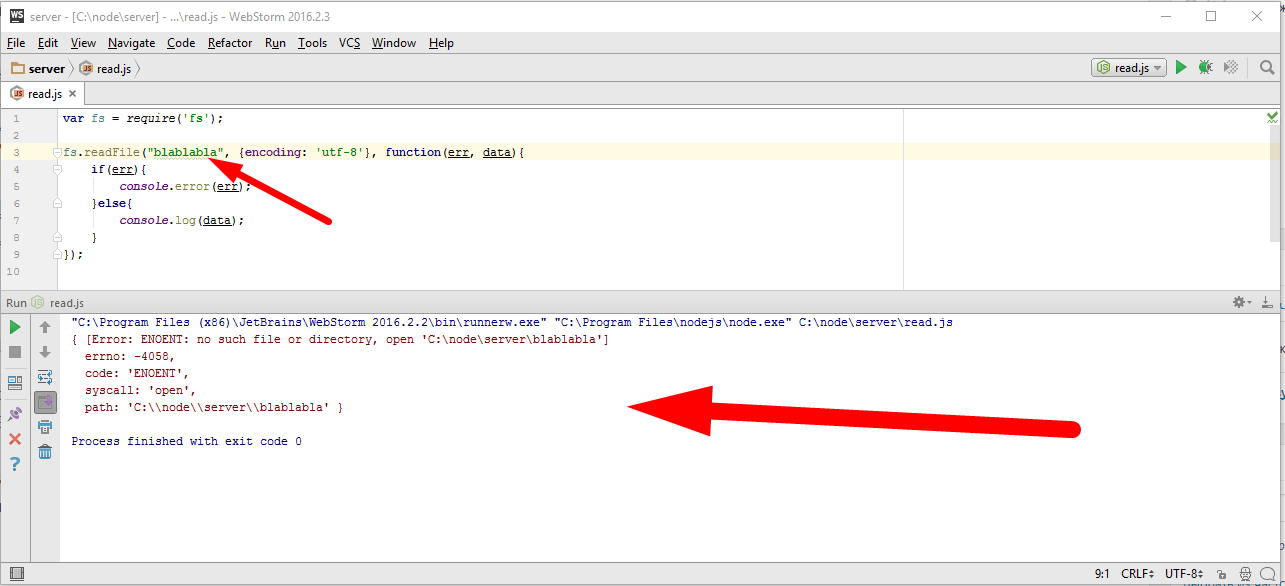
О! Вывелась ошибка в консоль Error. Обращаю ваше внимание, что в ошибке есть следующие данные:
Во первых, имя ошибки — code: ‘ENOENT’, в данном случае означает, что файла нет.
Во вторых это код цифровой — errno: -4058, и оба кода являются полностью кроссплатформенными, то есть не важно, под Windows, под Linux, еще под чем то я нахожусь, всегда если файл не найден, то это означает ошибка ‘ENOENT’. Соответственно мы можем проверить если код такой
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var fs = require('fs'); fs.readFile("blablabla", {encoding: 'utf-8'}, function(err, data){ if(err){ if(err.code == 'ENOENT'){ console.error(err.message); }else{ console.error(err); } }else{ console.log(data); } }); |
то обработать его определенным образом, а иначе сделать что то еще.
Если в будущем вас заинтересует какие еще ошибки есть, или вы захотите получить расшифровку какого то кода ошибки, то к сожалению в документации к Node.JS эта информация отсутствует. Но вы найдет ее в исходниках к библиотеки LibUV. Эти коды находятся именно здесь, потому что за ввод вывод отвечает библиотека LibUV и она трансформирует различные коды операционных систем в вот такие кроссплатформенные значения.
Если мы заведомо знаем, что файл может не существовать, то мы можем проверить его при помощи специального вызова. Для этого есть вызов fs.stat(path, callback) и различные его варианты, которые вы можете более подробно изучит в документации. Как правило в большинстве ситуаций подходит просто stat. Он получает путь и возвращает объект специального типа fs.Stats, который содержит подробную информацию о том, что по нему находится. Вот пример его использования
|
1 2 3 4 5 6 |
var fs = require('fs'); fs.stat(__filename, function(err, stats){ console.log(stats.isFile()); console.log(stats); }) |
запускаю
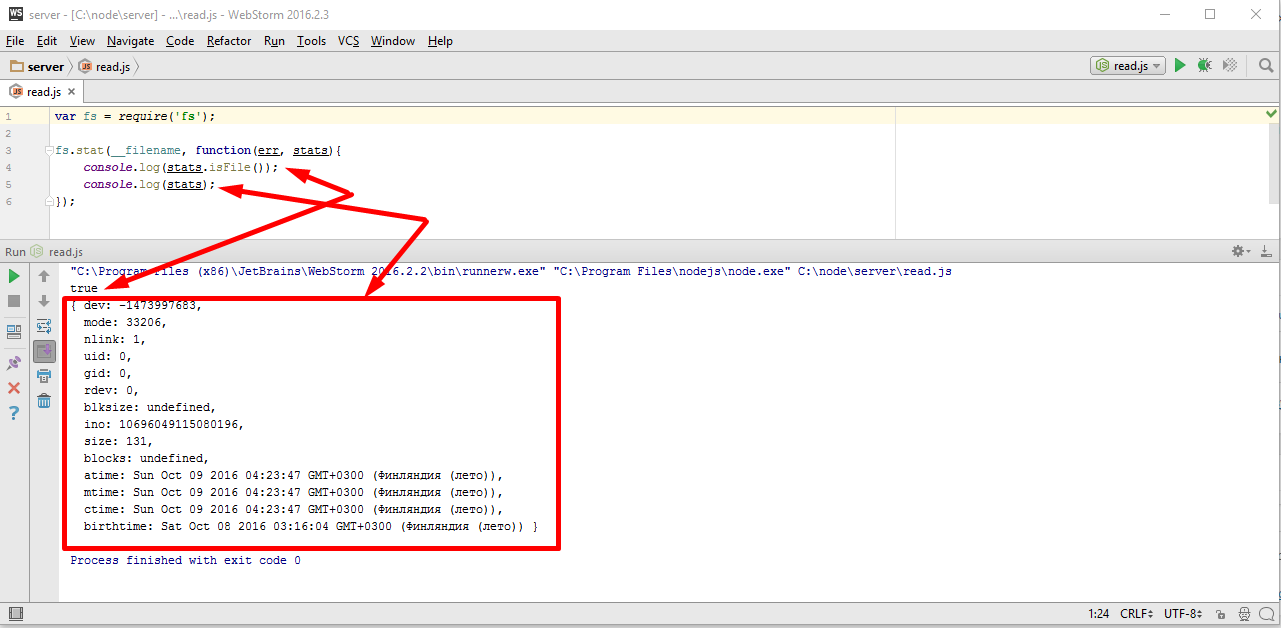
console.log первый, вывело true, по тому что это файл, а второй вывел полную информацию о том, что такое находится по данному пути, это немножко зависит от операционной системы, от файловой системы, но практически всегда есть размер — size, а также модификация — mtime и дата создания — ctime.
А вот пример создания нового файла, в котором будет содержаться строка data, после чего мы его переименовываем, а после переименования удаляем.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
var fs = require('fs'); fs.writeFile("file.tmp", "data", function(err){ if(err)throw err; fs.rename("file.tmp", "new.tmp", function(err){ if(err) throw err; fs.unlink("new.tmp", function(err){ if(err) throw err; }); }); }); |
Обратите внимание, что в каждом callback я проверяю ошибку, то есть после того как файл создан, я обязательно проверяю, если есть ошибка, нужно ее как то обработать, самый простейший способ это throw. Везде, в каждом callback должна быть обработка ошибок. Потому что ошибки могут быть в самых непредсказуемых местах.
Итак мы кратко познакомились с основными возможностями модуля «FS» и с некоторыми примерами их применения. Вообще же у этого модуля действительно очень много методов, я рекомендую посмотреть их в документации, просто, чтоб понимать, что вообще существует.
спасибо!