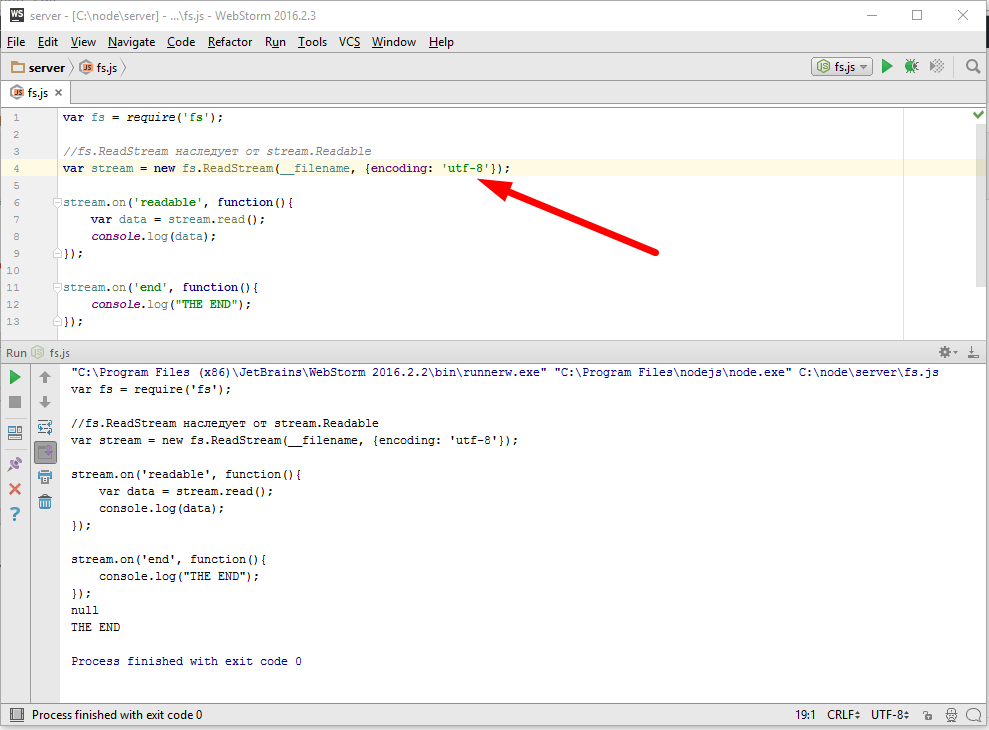
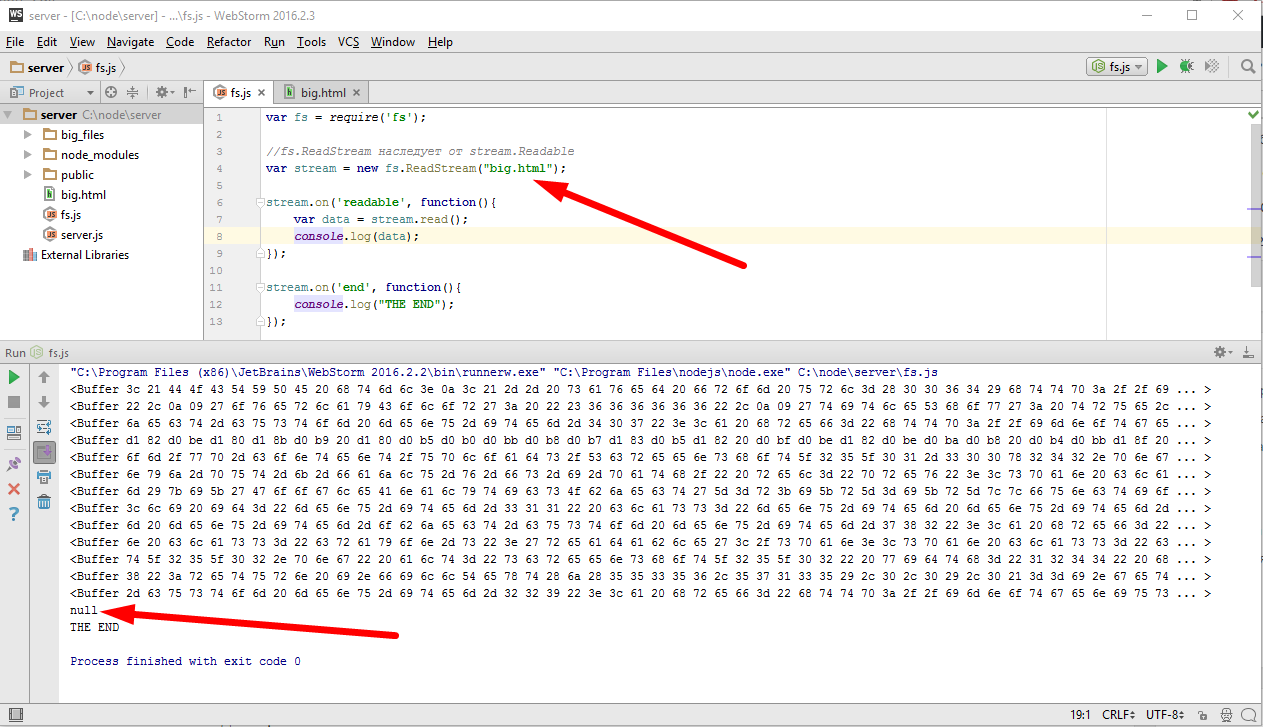
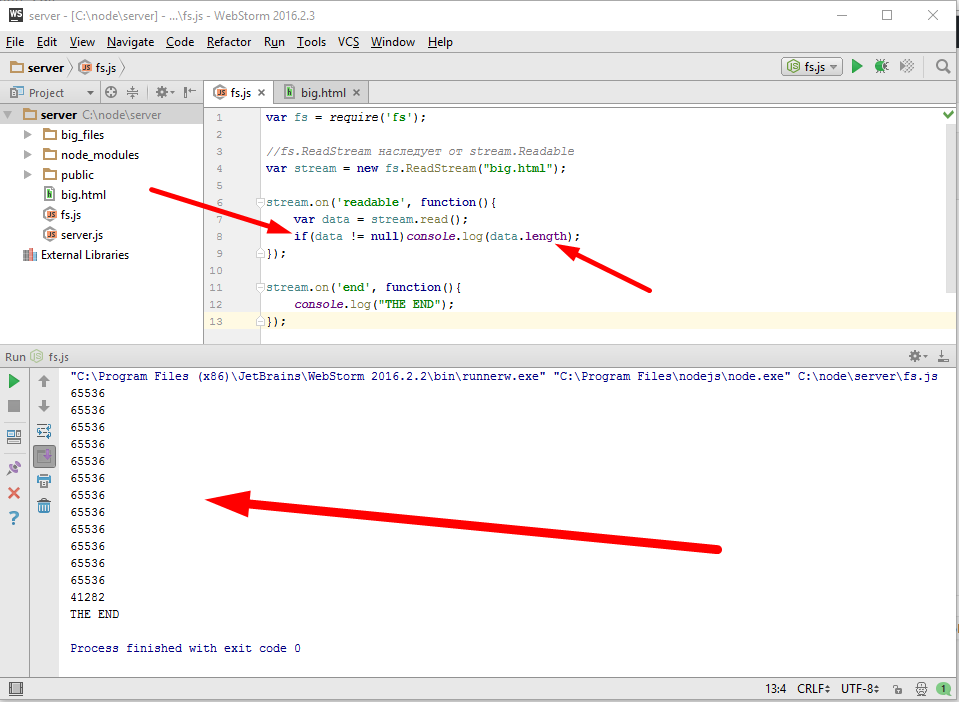
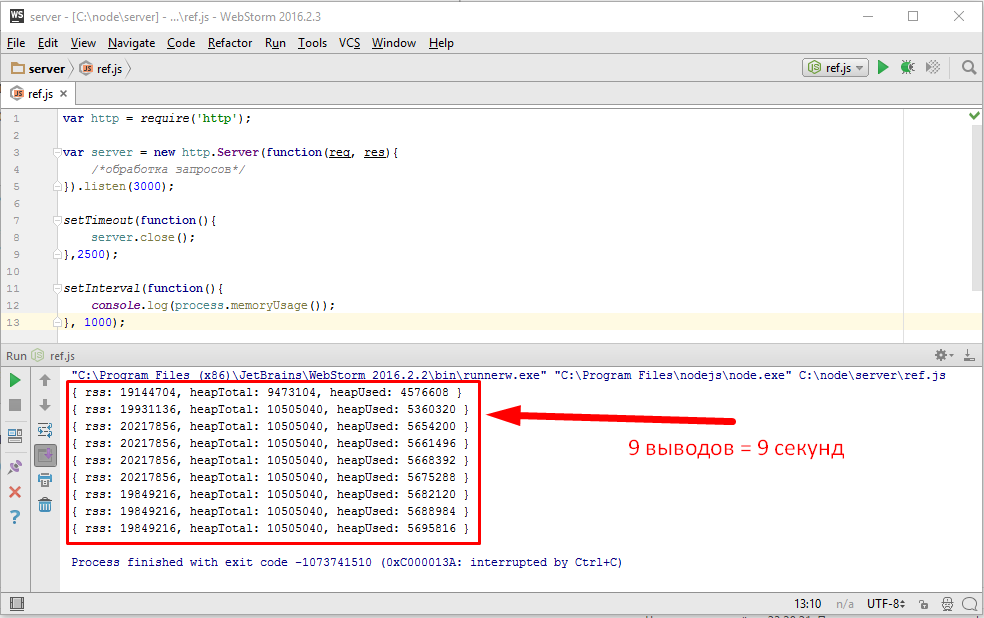
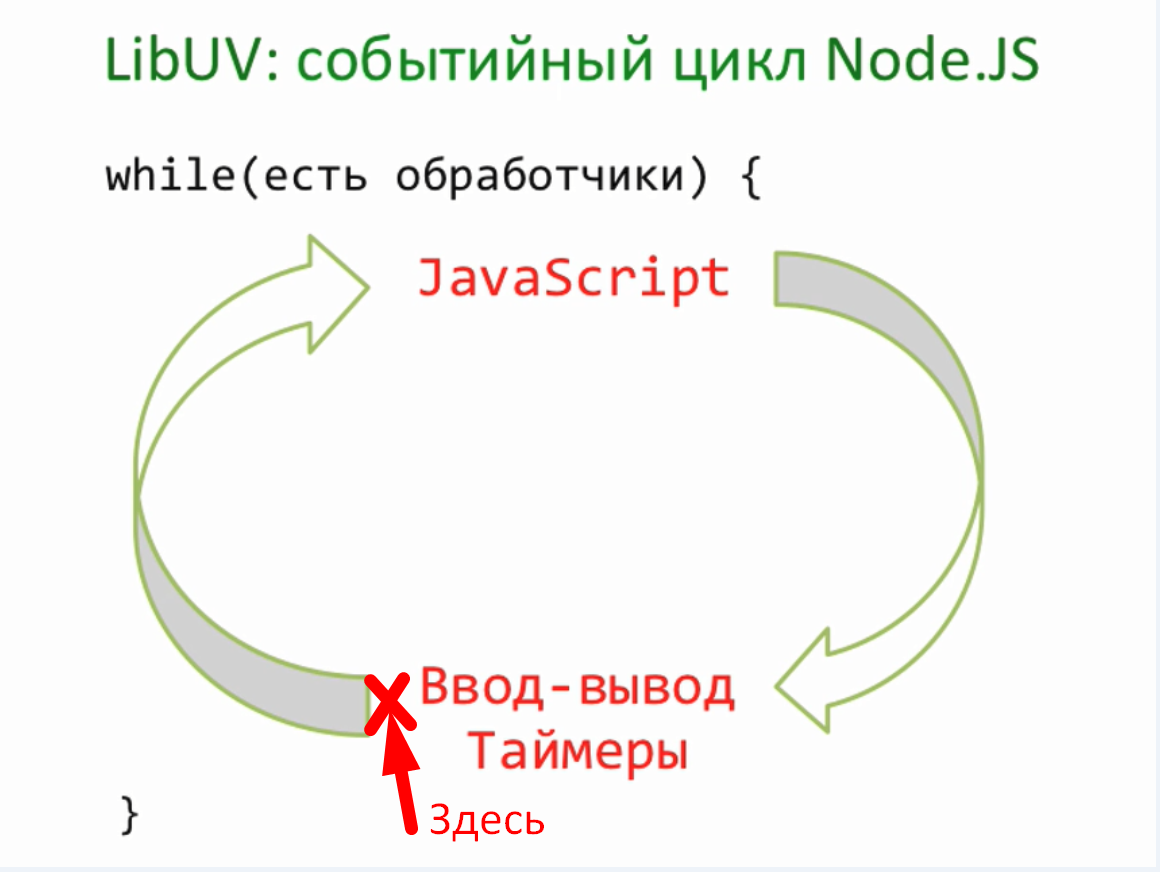
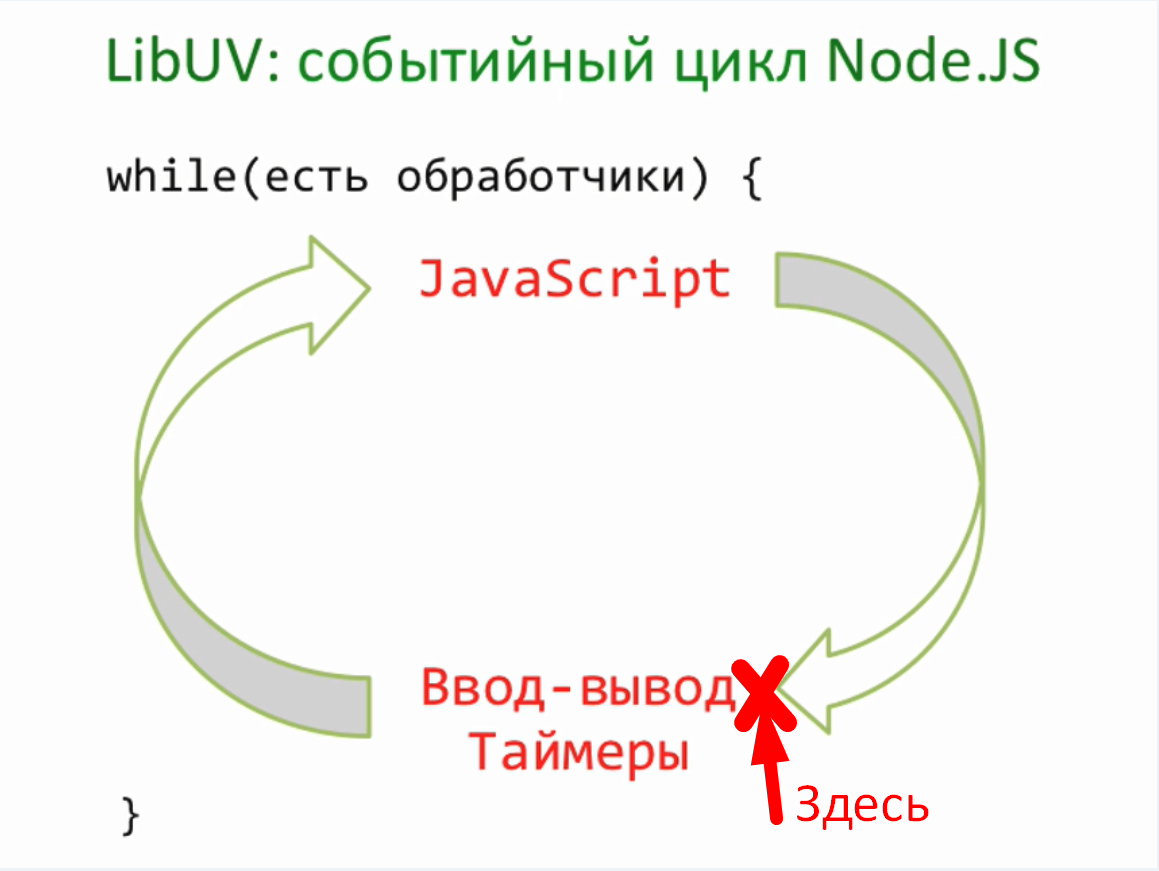
Нашим следующим шагом будет использование потоков для работы с сетевыми соединениями и начнем мы с отдачи посетителю файлов. Если помните у нас была такая задача, если посетитель запросит соответствующий url, то отдать ему файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
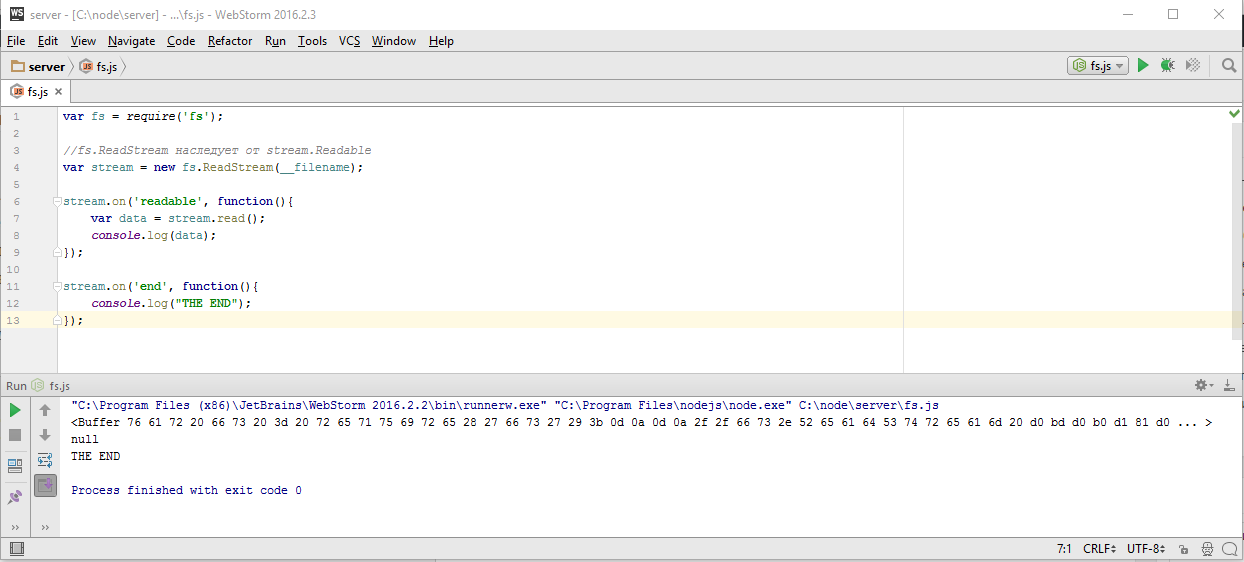
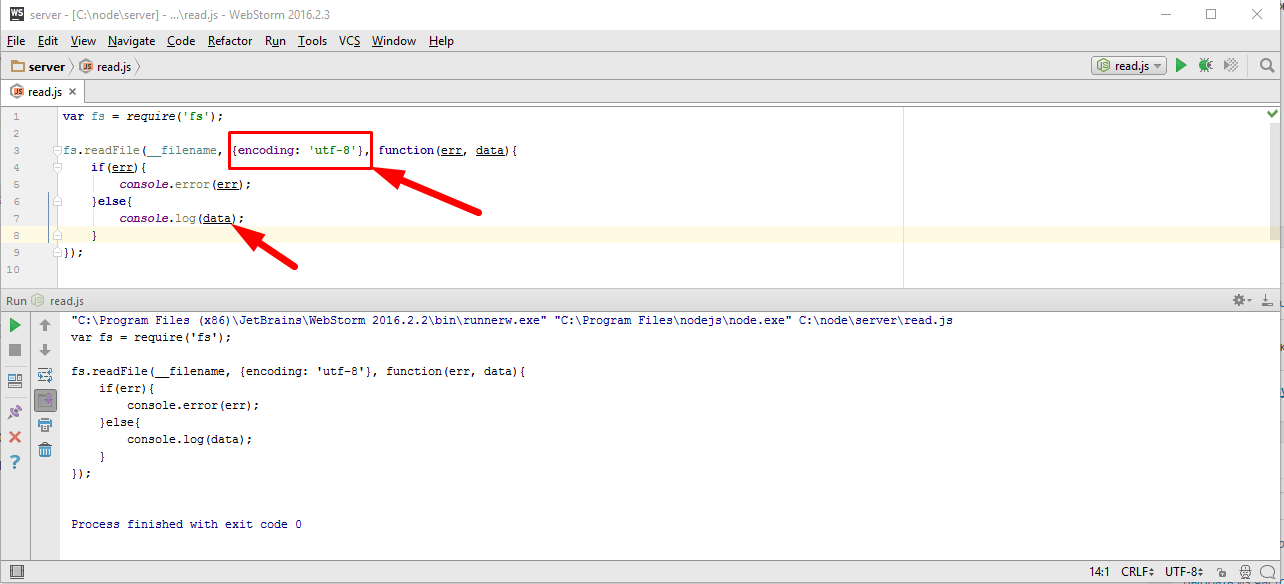
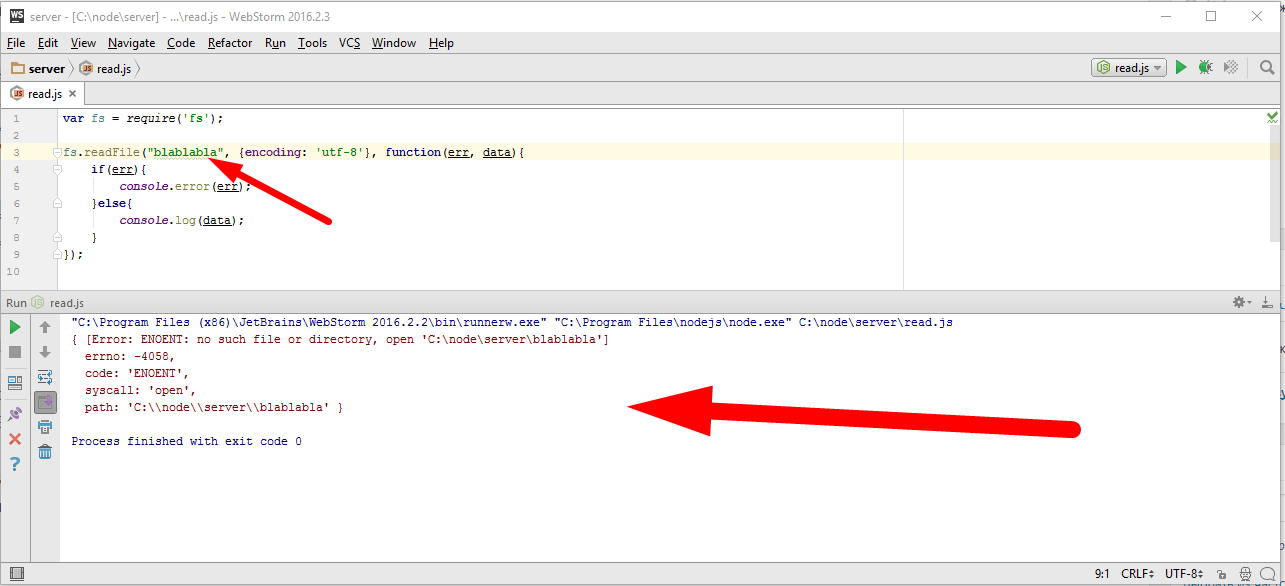
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ fs.readFile('big.html', function(err, content){ if(err){ res.statusCode = 500; res.end("Server error"); }else{ res.setHeader("Content-Type", "text/html; charset=utf-8"); res.end(content); } }); } }).listen(3000); |
Пример решения этой задачи без потоков может быть таким
|
|
fs.readFile('big.html', function(err, content){ if(err){ res.statusCode = 500; res.end("Server error"); }else{ res.setHeader("Content-Type", "text/html; charset=utf-8"); res.end(content); } }); |
читаем файл, когда файл прочитается, вызываем callback. Дальше при ошибке сообщаем о ней,
|
|
if(err){ res.statusCode = 500; res.end("Server error"); |
а если все хорошо, то ставим заголовок, чтоб указать какой это файл
|
|
}else{ res.setHeader("Content-Type", "text/html; charset=utf-8"); |
и записываем содержимое файла в ответ вызовом
который отдает content и завершает соединение.
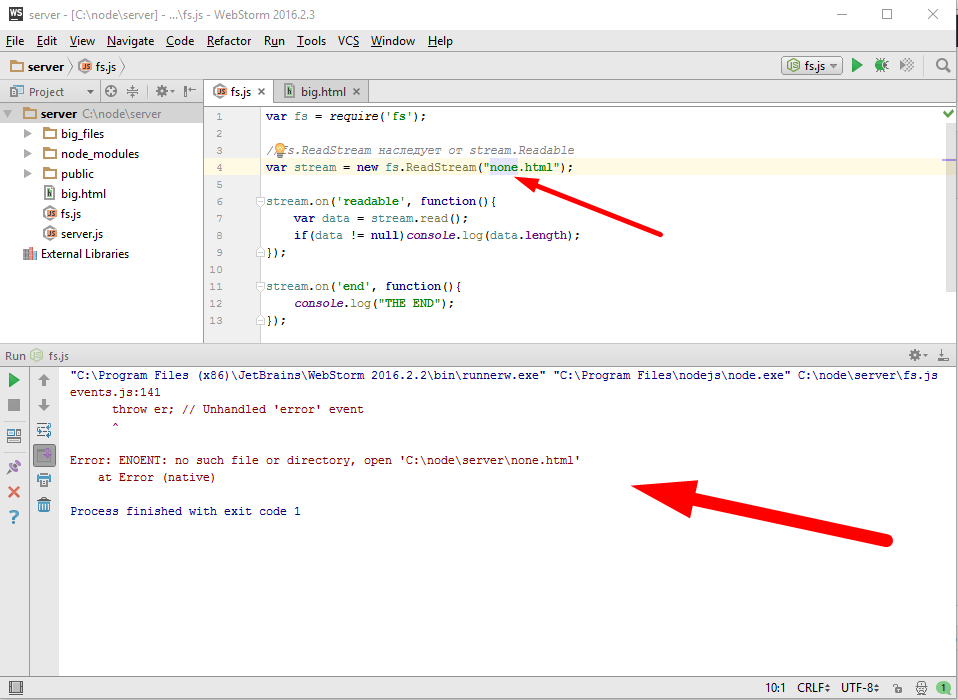
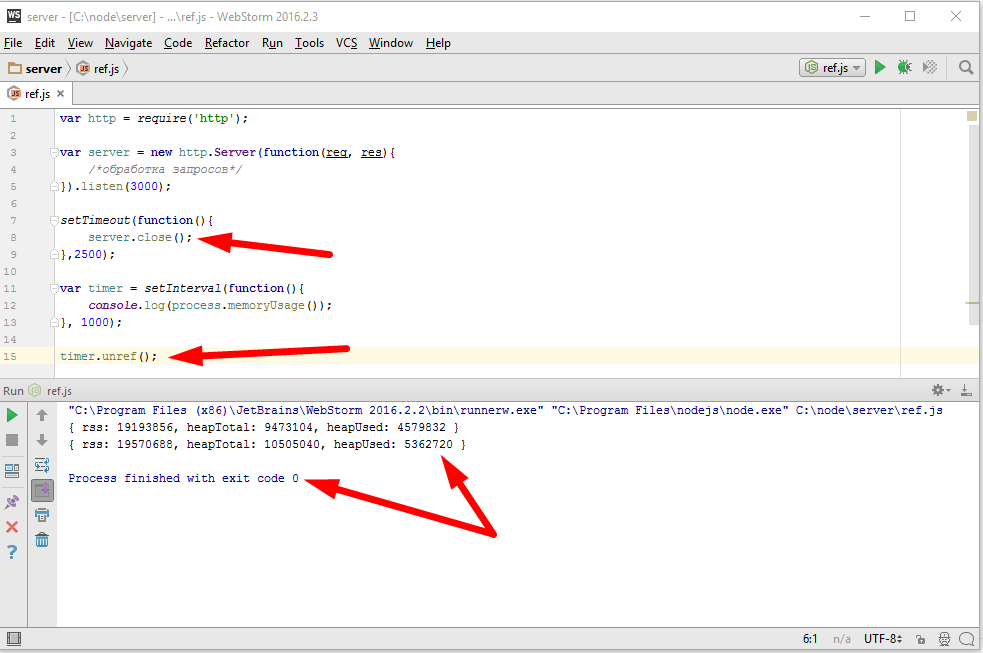
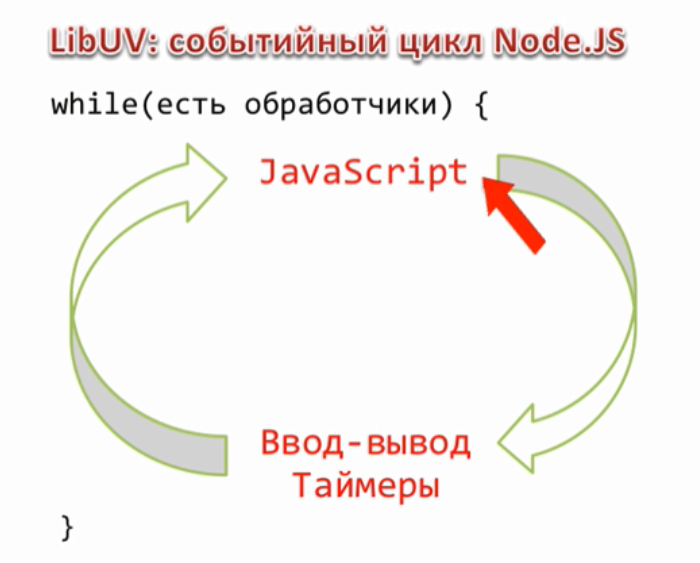
Это решение в принципе работает, но его проблема, это пожирание памяти. Потому что, если файл большой, то readFile его сначала считает, а потом вызовет callback, в результате получится, что если клиент медленный, то весь этот считанный content зависнет в памяти до того пока клиент его получит. А что если у нас таких медленных клиентов много? А если файл очень большой? Получается, что сервер может почти мгновенно занять всю доступную память, что конечно же совершенно не приемлемо. Чтобы такого не происходило, мы заменим код отдачи файла на принципиально другой, использующий потоки.
|
|
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); } }).listen(3000); |
Мы уже умеем читать из файла используя ReadStream, это будет входным потоком данных, а выходным будет объект ответа «res», который является объектом класса ServerResponse наследующим от stream.Writable. Общий алгоритм использования потоков для записи сильно отличается от того, что мы рассматривали ранее и выглядит так
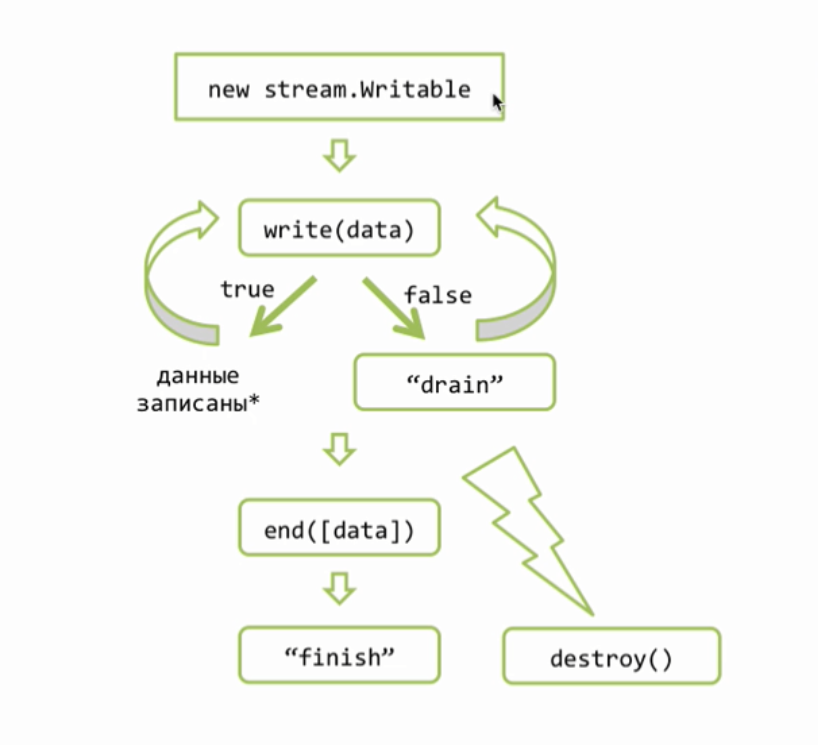
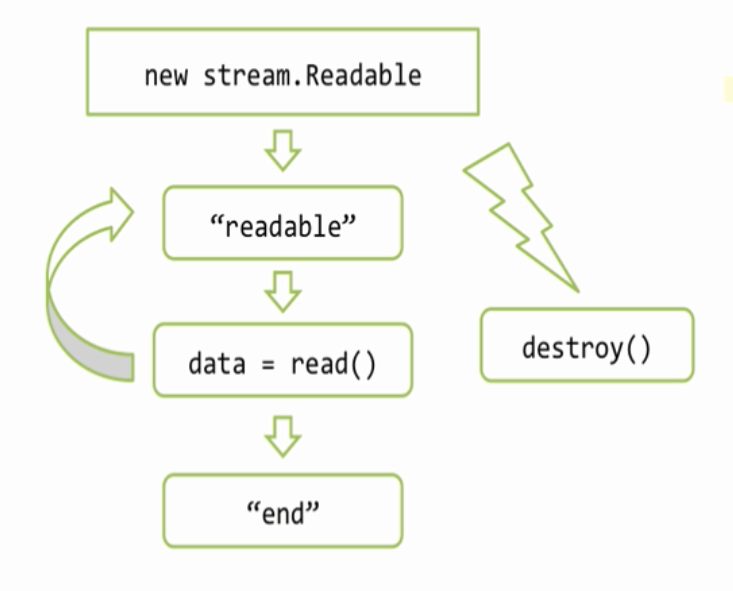
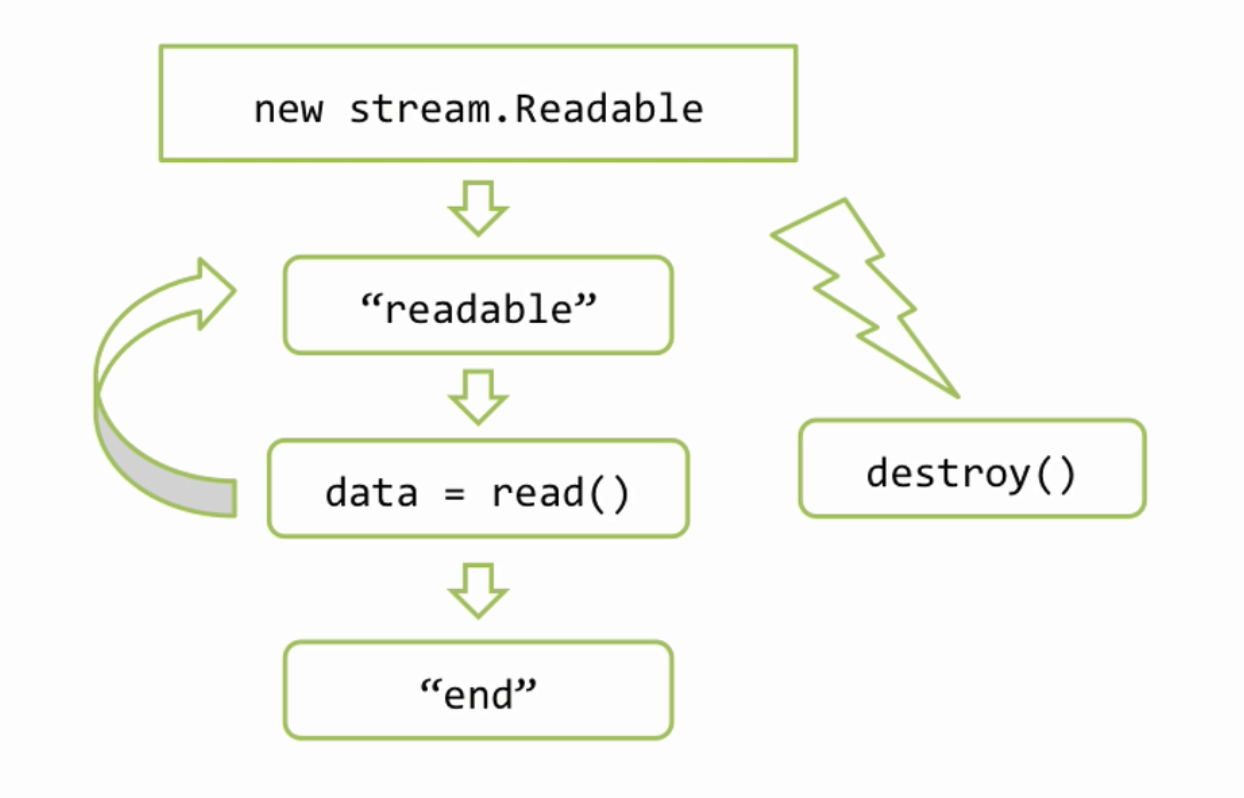
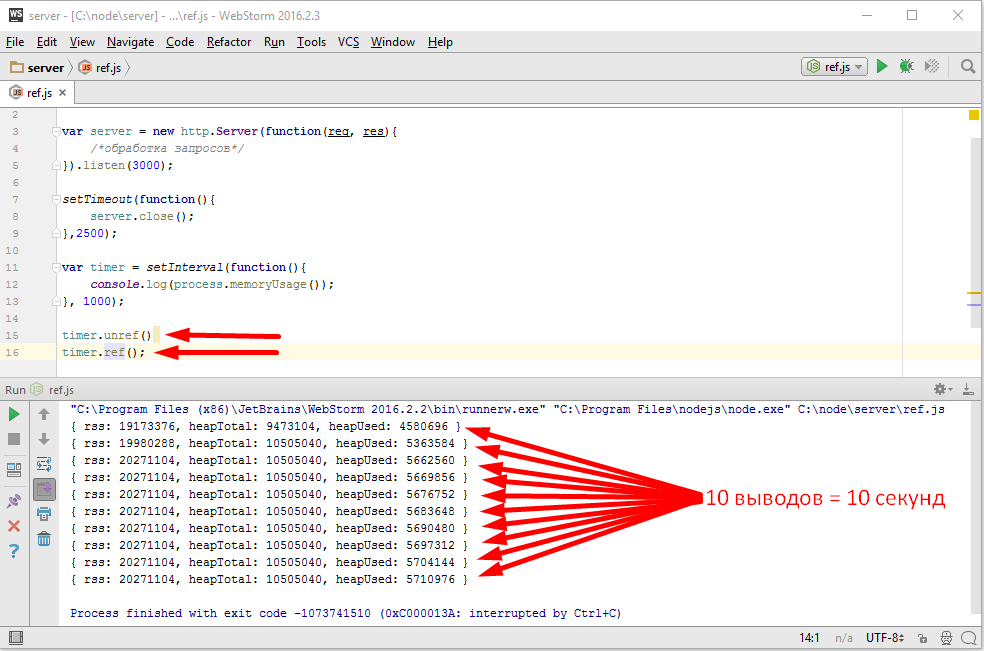
В начале мы создаем объект потока, если у нас http.Server, то этот объект уже создан, это res. Дальше мы хотим отправить что то клиенту, это можно сделать вызовом res.write и передать там наши данные, обычно это либо буфер, либо строка. Наши данные при этом добавляются к специальному свойству потока, которое называют его буфером. Если, пока, этот буфер не очень большой, то данные прибавляются к нему и write возвращает true, что означает, что мы можем писать еще, при этом обязательство по отсылке данных берет на себя поток, как правило эта отсылка происходит асинхронно. Возможен другой вариант, например если мы передали очень много данных или если буфер уже был чем то занят, то метод write() может вернуть false. False означает, что внутренний буфер потока переполнен и прямо сейчас запись конечно можно сделать, но это будет не целесообразно, потому что в буфере все будет просто копиться, копиться, копиться, по этому при получении false, обычно запись не продолжают, а ждут специального события «drain», которое будет сгенерировано потоком когда он все отошлет, то есть когда его внутренний буфер опустеет. Таким образом мы можем вызывать write много, много раз и когда мы понимаем, что всё, все данные записаны, то мы должны вызвать метод end(), тут тоже можем передать с первым аргументом данные — end([data]), в этом случае он просто write вызовет, самая главная задача end() это закончить запись. Поток это делает, при необходимости вызывает внутренние операции закрытия ресурсов, то есть файлов, соединений и так далее и затем генерирует событие finish, что означает, запись полностью завершена. Обращаю ваше внимание, что аналогичное событие у stream.Readable называется end(), это различие не случайно, потому что есть потоки дуплекс, которые умеют и читать и писать соответственно они могут генерировать как одно событие и другое.
Поток в любой момент можно разрушить вызовом метода destroy(), при вызове этого метода, работа потока прекращается и все ассоциированные с ним ресурсы будут освобождены. Конечно же событие «finish» уже никогда не состоится, потому что finish, это успешное окончание работы потока. Успешная отдача всех данных.
Реализуем успешную передачу всех данных используя эту схему
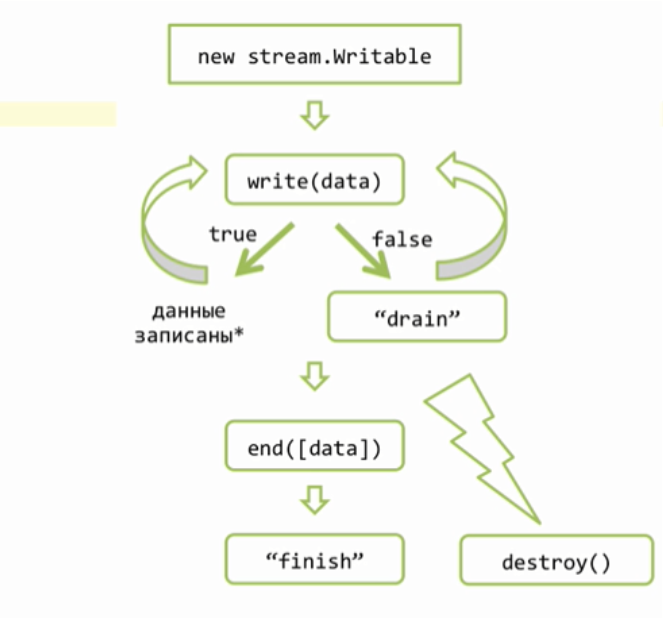
Я буду делать это в отдельной функции, которая будет называться sendFile(), она будет принимать один поток для файла и второй поток для ответа.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.on('readable', write); function write(){ var fileContent = file.read(); res.write(filrContent); } } |
Первое, что мы будем делать с такой функцией это ждать данных, затем когда они получены, то внутри обработчика readable читать их и отправлять в ответ
|
|
function write(){ var fileContent = file.read(); res.write(filrContent); } |
Конечно же она не выдерживает ни какой критики, поскольку в том случае, если клиент пока не может получить эти данные, например потому что у него медленная скорость соединения, то они зависнут в буфере объекта res, таким образом, если файл очень быстро считан, но пока не отправлен, то он займет большое количество памяти, а этого мы как раз хотели бы избежать.
В этом небольшом коде изложен пример более универсального решения этой задачи
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.on('readable', write); function write(){ var fileContent = file.read(); if(fileContent && !res.write(fileContent)){ file.removeListener('readable', write); res.once('drain', function(){ file.on('readable',write); write(); }); } } } |
мы тоже читаем содержимое из файла на событии readable, но мы не просто отправляем его вызовом res.write(… ), а еще и анализируем, что этот вызов вернет. Если res принимает данные очень быстро, то res.write(…. ) будет возвращать true, это означает, что эта ветка if никогда не выполнится
|
|
if(fileContent && !res.write(fileContent)){ file.removeListener('readable', write); res.once('drain', function(){ file.on('readable',write); write(); }); } |
соответственно мы получим read, write, read, write и так далее. Более интересный случай когда res.write(… ) вернул false, то есть когда буфер переполнен, в этом случае, мы временно отказываемся обрабатывать события readable на файле
|
|
file.removeListener('readable', write); |
Само по себе, такое снятие обработчика не означает, что файловый поток перестанет читать данные, он будет читать данные, но он дочитает до определенного уровня, заполнит свой внутренний буфер объекта файл и затем, так как никто read не вызывает, то этот внутренний буфер останется заполненным на определенном уровне. То есть файловый поток что то считает и там застопорится, далее мы дождемся событие ‘drain’, то есть когда данные будут успешно отданы в ответ и когда данные отданы в ответ, это означает, что мы можем принять что то еще из файла, мы вновь показываем свой интерес в событиях ‘readable’ и вызываем метод write() сразу. Сразу, потому что пока мы ждали события ‘drain’ новые данные могли прийти, это означает, что имеет смысл их тут же прочитать, вызов read() вернет null если данных нет, ну а если есть, то они просто будут обработаны, тем же способом, о котором мы говорили раньше.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.on('readable', write); function write(){ var fileContent = file.read(); // Считать if(fileContent && !res.write(fileContent)){ // Отправить file.removeListener('readable', write); res.once('drain', function(){ // Подождать file.on('readable',write); write(); }); } } } |
Такая вот своеобразная рекурсивная функция получается — считать, отправить то что считано, при необходимости подождать ‘drain’, считать дальше, отправить, подождать и так далее по циклу, пока файл не закончится. По окончанию файла наступит событие ‘end’ в обработчике которого мы завершим ответ, вызовом res.end(), таким образом будет закрыто исходящее соединение, потому что файл полностью отослан.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.on('readable', write); function write(){ var fileContent = file.read(); // Считать if(fileContent && !res.write(fileContent)){ // Отправить file.removeListener('readable', write); res.once('drain', function(){ // Подождать file.on('readable',write); write(); }); } } file.on('end', function(){ res.end(); }); } |
Получившийся код является весьма универсальным, он реализует достаточно общий алгоритм отправки данных из одного потока в другой, используя самые стандартные методы потоков readable и writable. Об этом конечно же подумали и разработчики самого Node.JS и добавили его несколько более оптимизированную реализацию в стандартную библиотеку потоков. Соответствующий метод называется pipe(), он есть у всех readable потоков и работает так —

Кроме того, что это всего лишь одна строка тут есть еще один бонус, например можно один и тот же входной поток «пайпить» в несколько выходных, например кроме ответа клиенту, будем выводить его еще в стандартный вывод процесса. Давайте запустим такой код
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.pipe(res); file.pipe(process.stdout); } |
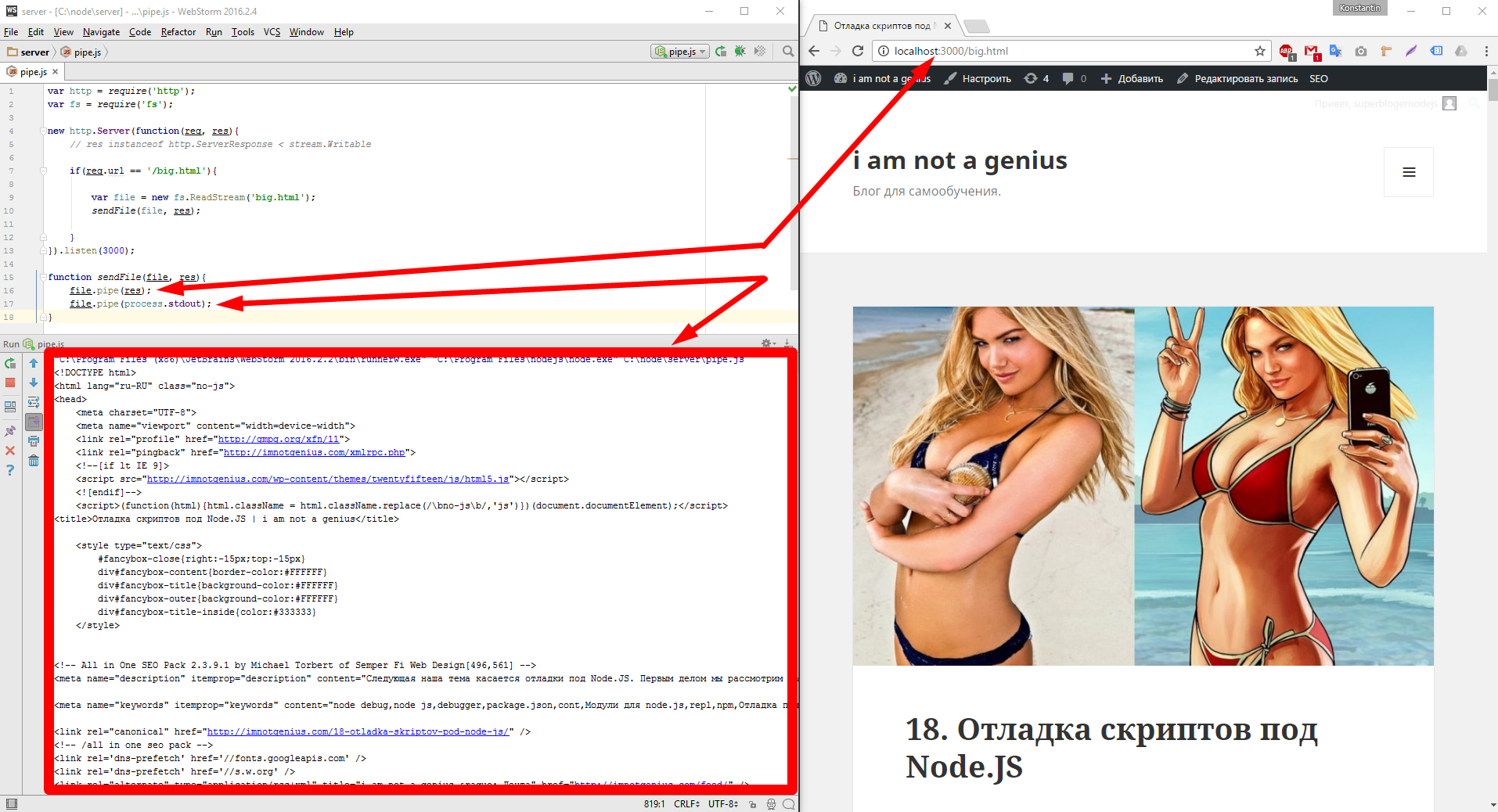
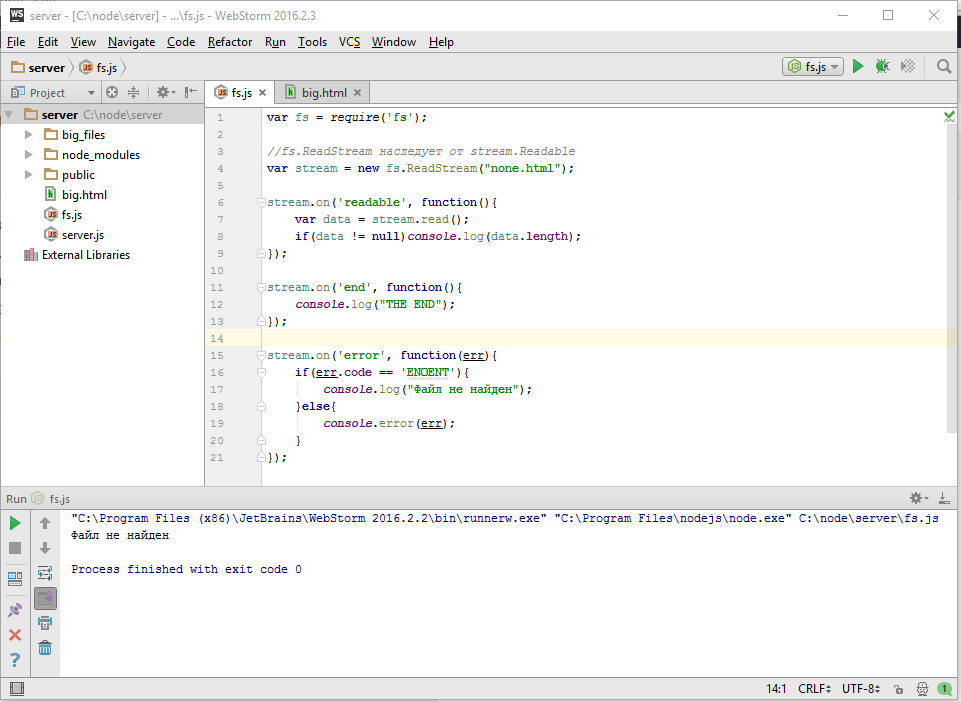
Вывелось и клиенту в браузер и в консоль нашей IDE. Готов ли этот замечательный код к промышленной эксплуатации? Есть ли еще какие то нюансы которые нужно учесть? Первым делом в глаза должна бросится работа с ошибками, если вдруг файл не найден или что то с ним не так, тогда упадет весь сервер вообще. Это не то что нам нужно, поэтому добавим обработчик, получаем это
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.pipe(res); file.on('error', function(err){ res.statusCode = 500; res.end("Server Error"); console.error(err); }); } |
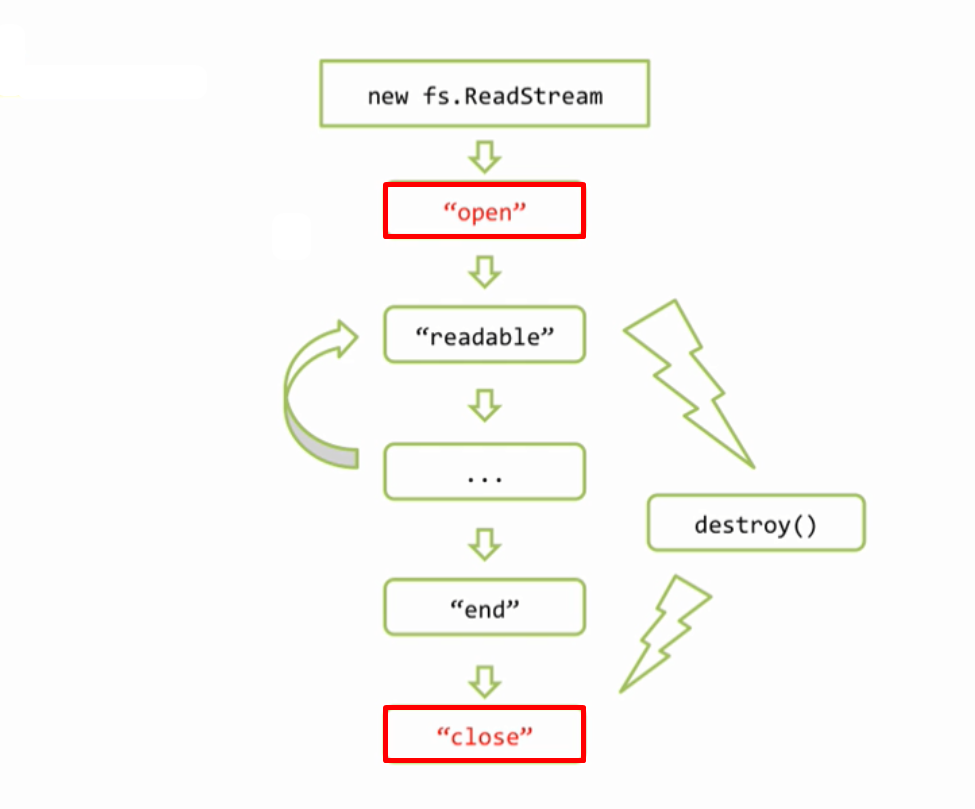
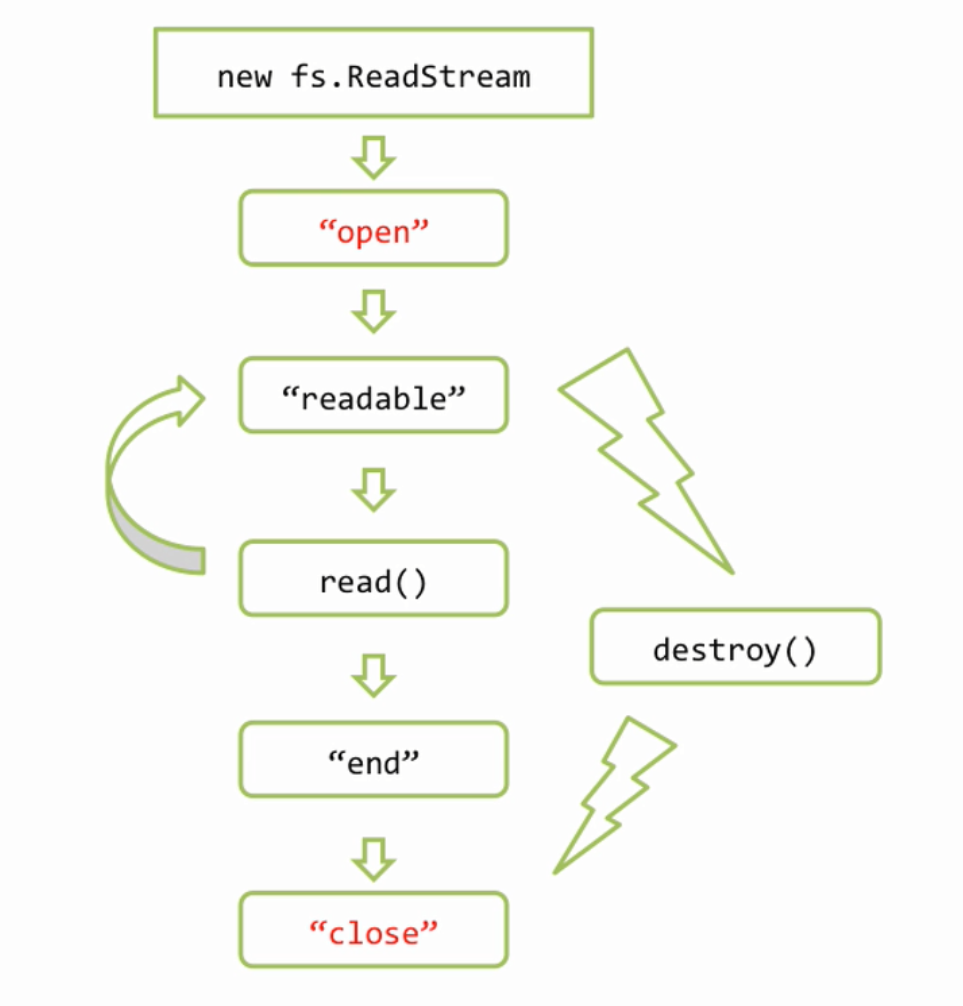
Что же, мы теперь немножко ближе к реальной жизни и в ряде руководств такой код выдается за вполне нормальный, но на самом деле это не так, ставить такой код на живой сервер ни в коем случае нельзя. В чем же дело? для того чтобы продемонстрировать проблему я сейчас добавлю дополнительные обработчики на события open и close для файла.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.pipe(res); file.on('error', function(err){ res.statusCode = 500; res.end("Server Error"); console.error(err); }); file .on('open', function(){ console.log("open"); }) .on('close', function(){ console.log("close"); }); } |
стартую и обновляю в браузере страницу, обновляю, обновляю несколько раз
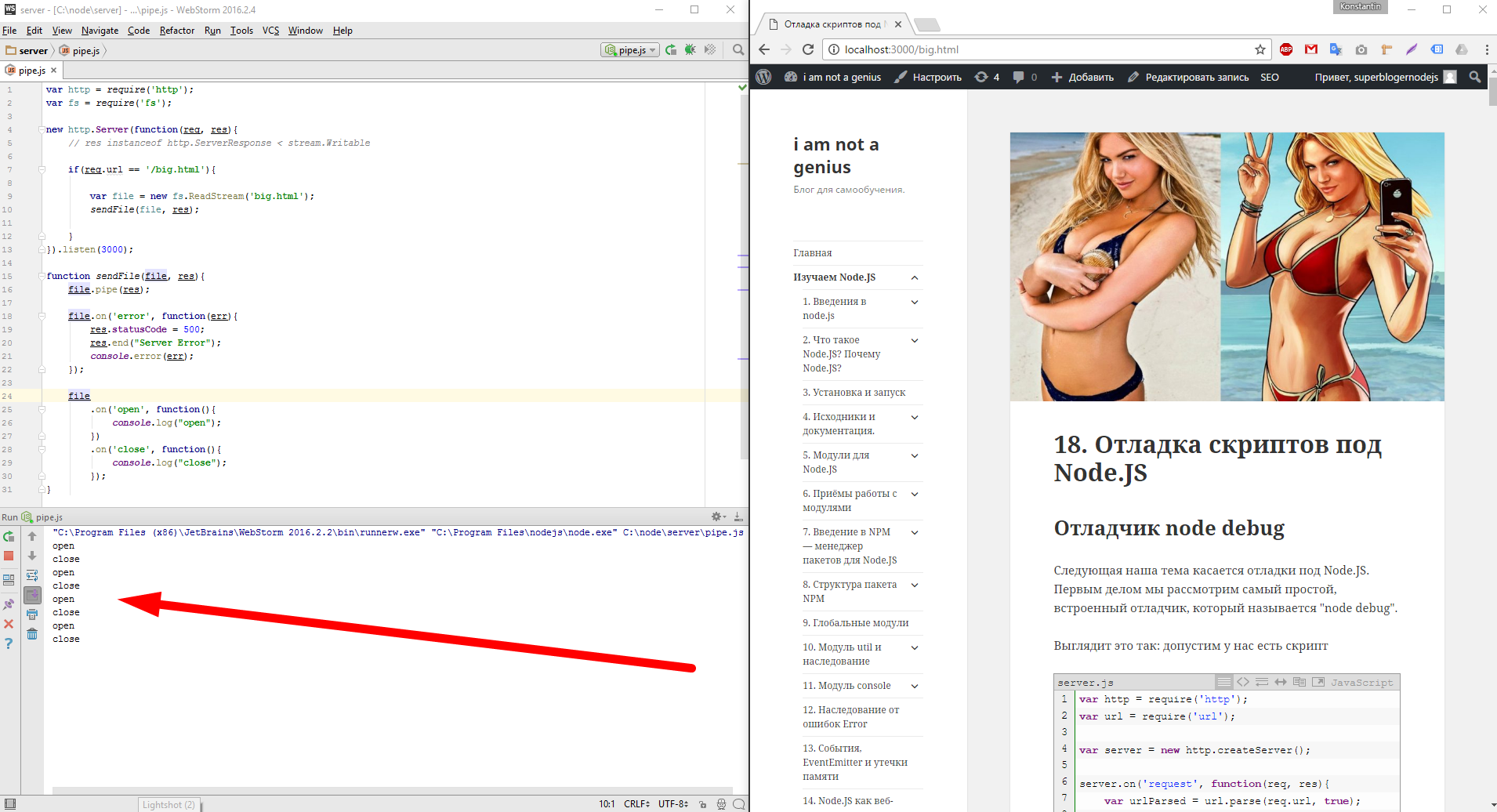
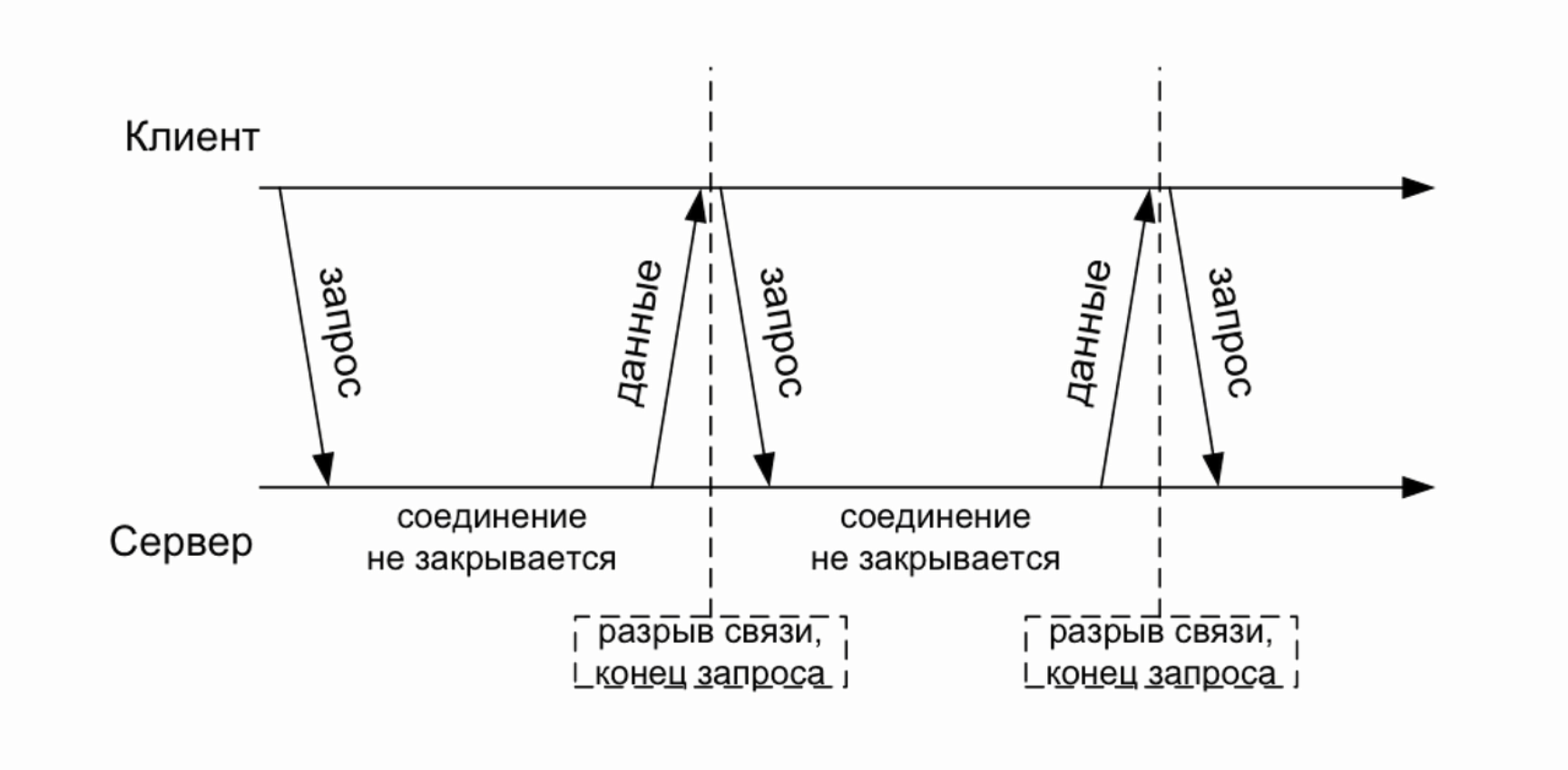
Видите файл перезагружается и совершенно нормально, то что файл открывается, потом он целиком отдается и закрывается. Теперь я открою консоль и запущу утилиту curl которая будет скачивать вот этот url — http://localhost:3000/big.html с ограничением скорости в один килобайт в секунду.
Давайте поставим эту утилиту. Для этого ищем в гугле curl
раз википедия, так википедия, там находим официальный сайт — https://curl.haxx.se/ и на нем во вкладке download в низу списка находим нашу винду и качаем архив

Распаковав архив в корень диска С: в директорию curl мы сначала устанавливаем сертификат безопасности кликнув по нему дважды, а потом прописываем в глобальную переменную path путь ко второму файлу в этой папке, к curl.exe, это нужно, чтоб я мог обращаться к этой утилите из консоли, то есть дописываем в path путь к папке, в которой находится наша утилита.
Продолжим, напомню у нас запущен сервер pipe.js и следим за консолью IDE, открыли окно команд в Windows, и вводим следующую команду
|
|
C:\Users\ASUS\Desktop>curl --limit-rate 1k http://localhost:3000/big.html |
Запустили, и открывается файл начинается получение, с виду все хорошо, но если нажать Ctrl+C, то есть прекратить загрузку, мы не увидим в консоле нашей IDE ни какого close
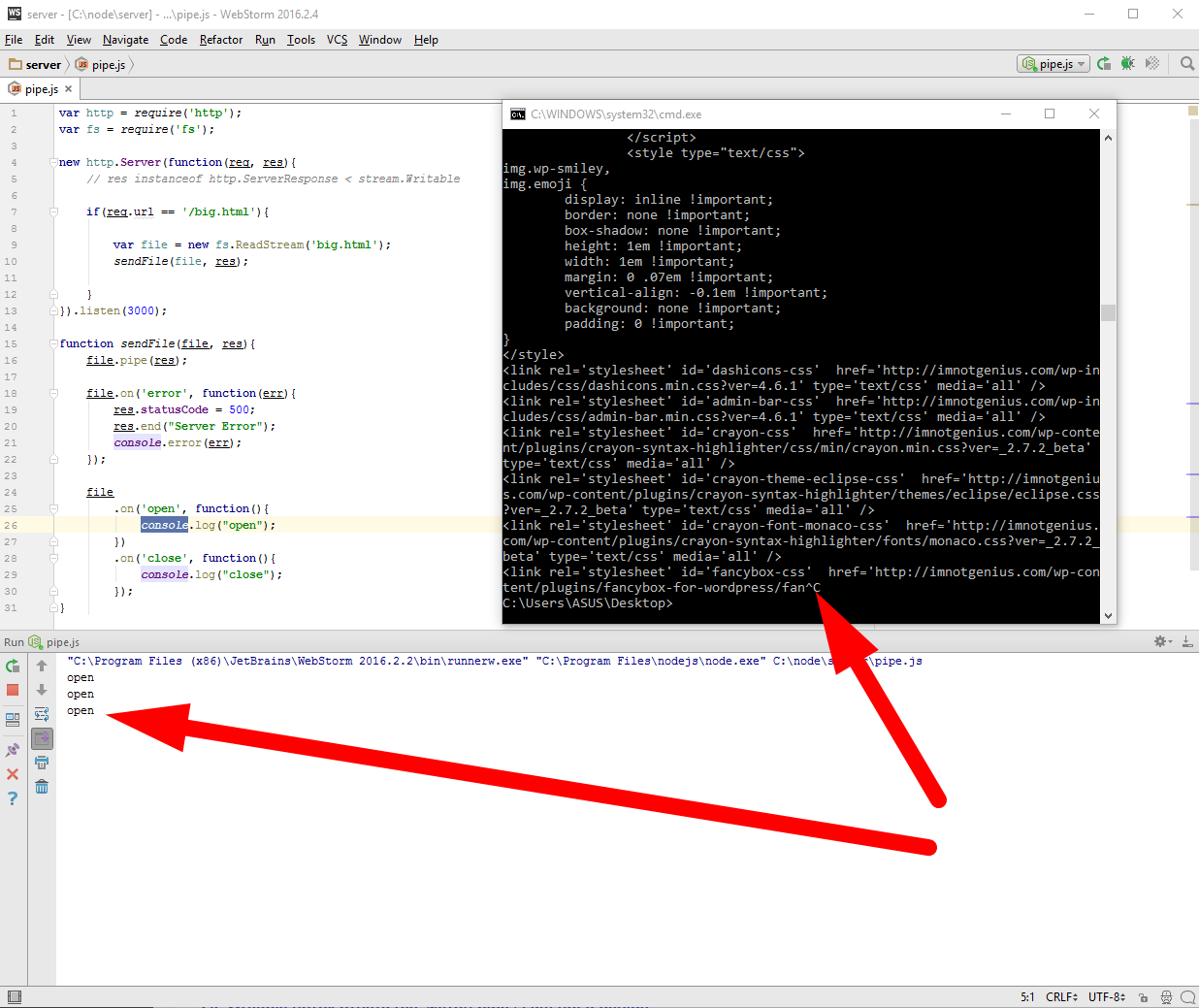
видите, я трижды начинал загрузку и прерывал, ни одного закрытия. Для того чтоб повторить эксперимент файл должен быть более 3Mb. Иначе говоря, если клиент открыл соединение, но закрыл его до того как загрузка файла была завершена, то получается что файл останется подвисшим. А если файл остался открытым, то во первых все ассоциированные с ним структуры остались тоже в памяти, во вторых в операционных системах зачастую есть лимит на количество одновременно открытых файлов. А в третьих вместе с файлом навечно зависает в памяти и соответствующий объект потока, а вместе с ним и все замыкание в котором он находится. Чтобы избежать этой проблемы и следствий, достаточно всего лишь отловить момент, когда соединение закрыто и при этом удостовериться, что файл тоже будет закрыт. Событие которое нас интересует, называется res.on(‘close’, ….) и это событие отсутствует в обычном Stream.writable, то есть это именно расширение стандартного интерфейса потоков, так же как у файла есть close — file.on(‘close’, …), так и у объекта ответа server response тоже есть close — res.on(‘close’, ….). Но смысл последнего сильно отличается от первого, это очень важно, потому что на файловом потоке ‘close’ это нормальное завершение, файл закрывается всегда в конце, а для объекта ответа, ‘close’ это сигнал о том, что соединение было оборвано, при нормально завершении происходит не ‘close’, а ‘finish’. Итак, если соединение было оборвано, то нам нужно закрыть файл и освободить все ресурсы, поскольку файл нам больше передавать некому, для этого мы вызываем метод потока file.destroy(); теперь все будет хорошо. Теперь давайте еще раз проверим
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
var http = require('http'); var fs = require('fs'); new http.Server(function(req, res){ // res instanceof http.ServerResponse < stream.Writable if(req.url == '/big.html'){ var file = new fs.ReadStream('big.html'); sendFile(file, res); } }).listen(3000); function sendFile(file, res){ file.pipe(res); file.on('error', function(err){ res.statusCode = 500; res.end("Server Error"); console.error(err); }); file .on('open', function(){ console.log("open"); }) .on('close', function(){ console.log("close"); }); res.on('close', function(){ file.destroy(); }); } |
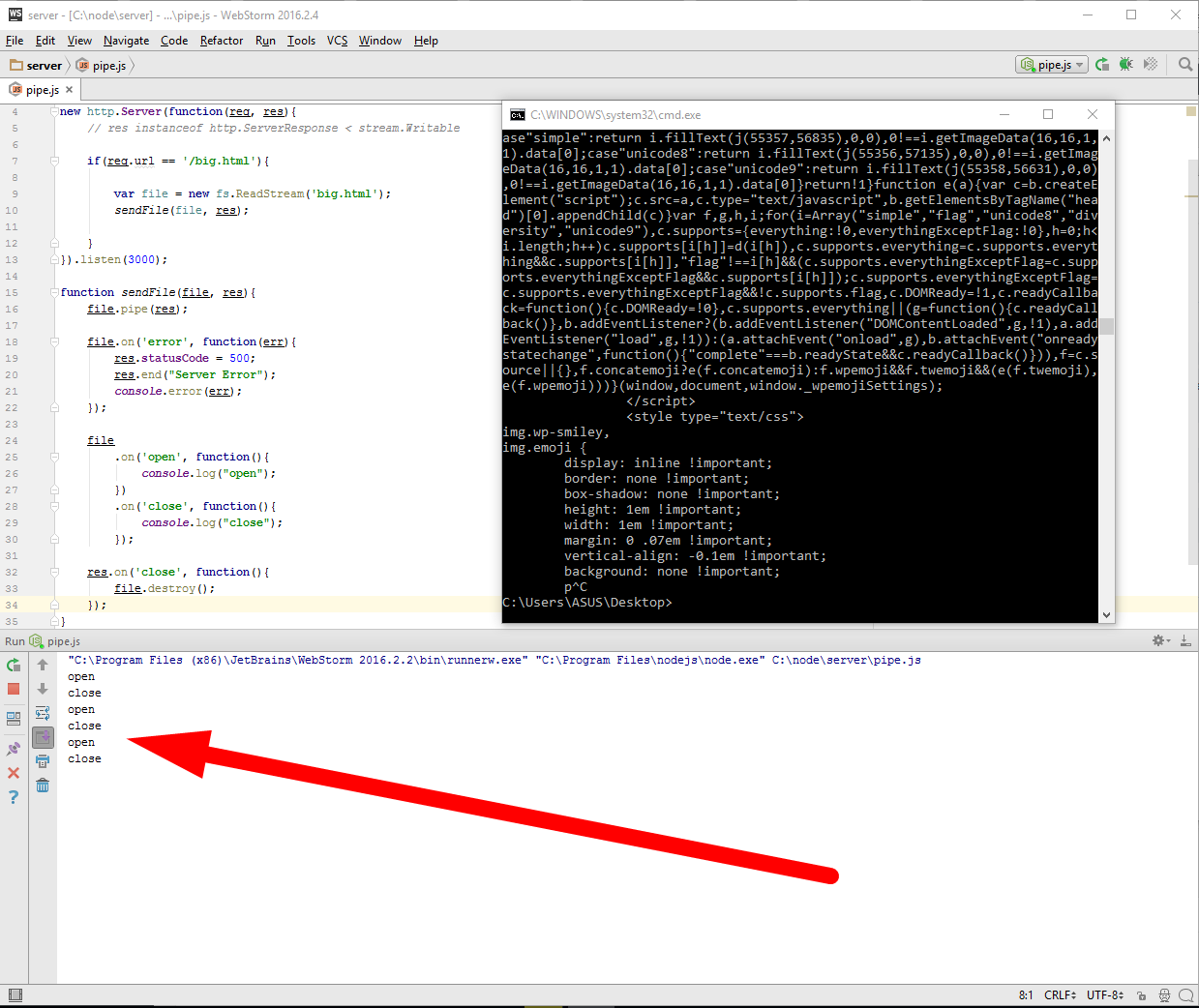
Теперь наш код можно пускать на живой сервер.