
Тема этой главы, потоки в Node.JS. Мы постараемся разобраться в этой теме хорошо и подробно, по сколько, с одной стороны , так получается, что потоки в обычной браузерной JavaScript разработке отсутствуют, а с другой стороны, уверенное владение потоками необходимо для грамотной серверной разработке, по скольку поток, является универсальным способом работы с источниками данных, которые используются повсеместно.
Можно выделить два основных типа потоков.
Первый поток — stream.Readable — чтение.
stream.Readable это встроенный класс, который реализует потоки для чтения, как правило сам он не используется, а используются его наследники. В частности для чтения из файла есть fs.ReadSream. Для чтения запроса посетителя, server.on(‘request’, …req…), при его обработки, есть специальный объект, который мы раньше видели под именем req, первый аргумент обработчика запроса.
Второй поток — stream.Writable — запись.
stream.Writable это универсальный способ записи и здесь тоже, сам stream.Writable обычно не используется, но используются его наследники.
…в файл: fs.WriteStream
…в ответ посетителю: server.on(‘request’, …res…)
Есть и некоторые другие типы потоков, но наиболее востребованные это предыдущие два и производные от них.
Самый лучший способ разобраться с потоками это посмотреть как они работают на практике. Поэтому сейчас мы начнем с того, что используем fs.ReadStream для чтения файла.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var fs = require('fs'); //fs.ReadStream наследует от stream.Readable var stream = new fs.ReadStream(__filename); stream.on('readable', function(){ var data = stream.read(); console.log(data); }); stream.on('end', function(){ console.log("THE END"); }); |
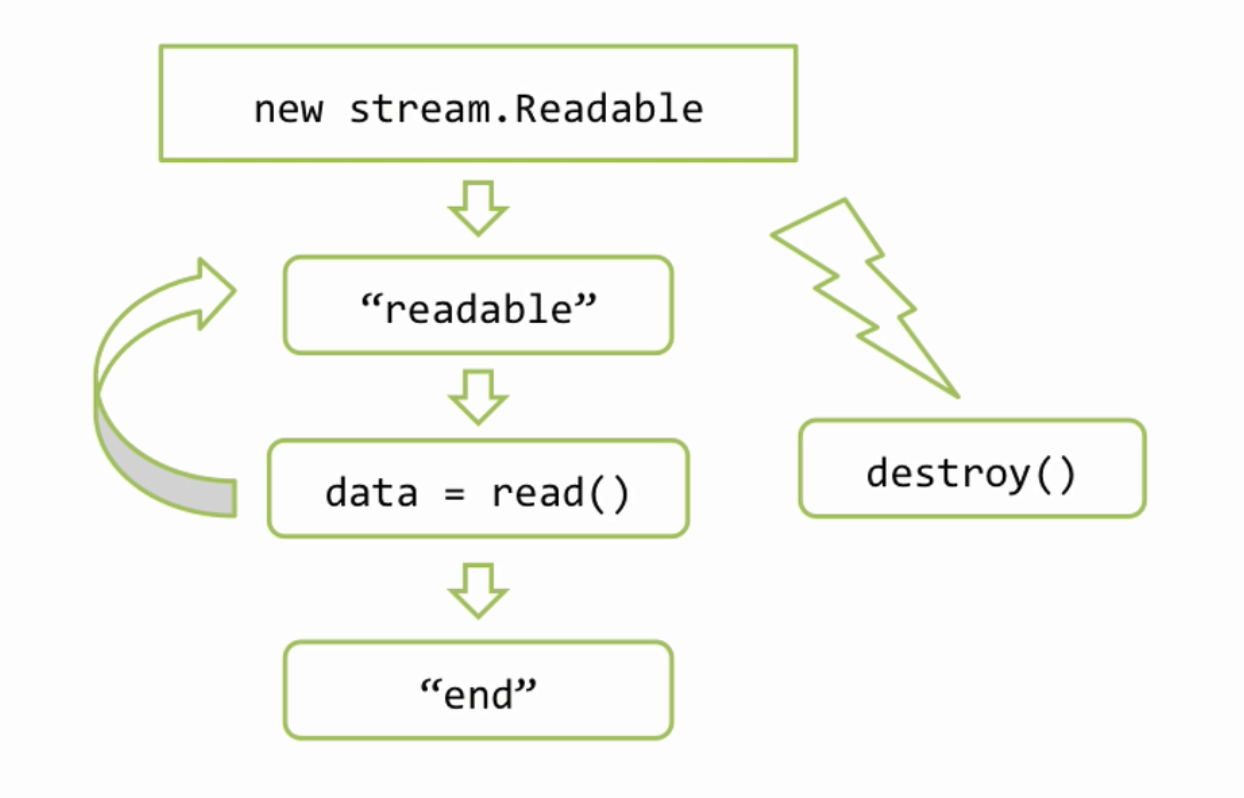
Итак, здесь я подключаю модуль fs и создаю поток. Поток это JavaScript объект, который получает информацию о ресурсе, в данном случае путь к файлу — «__filename» и который умеет с этим ресурсом работать. fs.ReadStream реализует стандартный интерфейс чтения который описан в классе stream.Readable. Посмотрим его на схеме
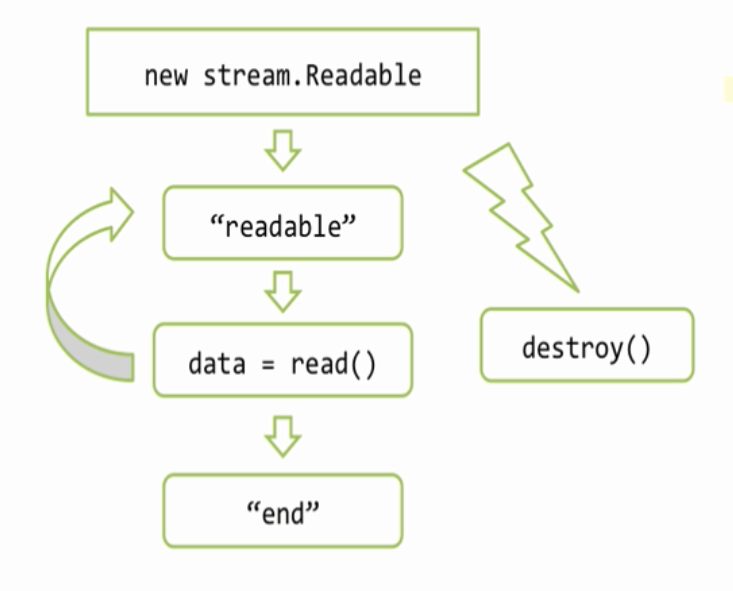
Когда создается объект потока — «new stream.Readable», он подключается к источнику данных, в нашем случае это файл, и пытается начать из него читать. Когда он что то прочитал, то он эмитирует событие — «readable», это событие означает, что данные просчитаны и находятся во внутреннем буфере потока, который мы можем получить используя вызов «read()». Затем мы можем что то сделать с данными — «data» и подождать следующего «readable» и снова если придется, и так дальше. Когда источник данных иссяк, бывают конечно источники которые не иссякают, например датчики случайных чисел, но размер файла то ограничен, поэтому в конце будет событие «end», которое означает, что данных больше не будет. Так же, на любом этапе работы с потоком, я могу вызвать метод «destroy()» потока. Этот метод означает, что мы больше не нуждаемся в потоке и можно его закрыть, и закрыть соответствующие источники данных, полностью все очистить.
А теперь вернемся к исходному коду. Итак здесь мы создаем ReadStream
|
3 4 5 |
//fs.ReadStream наследует от stream.Readable var stream = new fs.ReadStream(__filename); |
и он тут же хочет открыть файл. Но тут же, в данном случае вовсе не означает на этой же строке, потому что как мы помним, все операции с вводом выводом, реализуются через «LibUV», а «LibUV» устроено так, что все синхронные обработчики ввода вывода сработают на следующей итерации событийного цикла, то есть заведомо после того, как весь текущий JavaScript закончит работу. Это означает, что я могу без проблем навесить все обработчики и я твердо знаю что они будут установлены до того как будет считан первый фрагмент данных. Запускаю этот код и смотрим, что вывелось в консоле
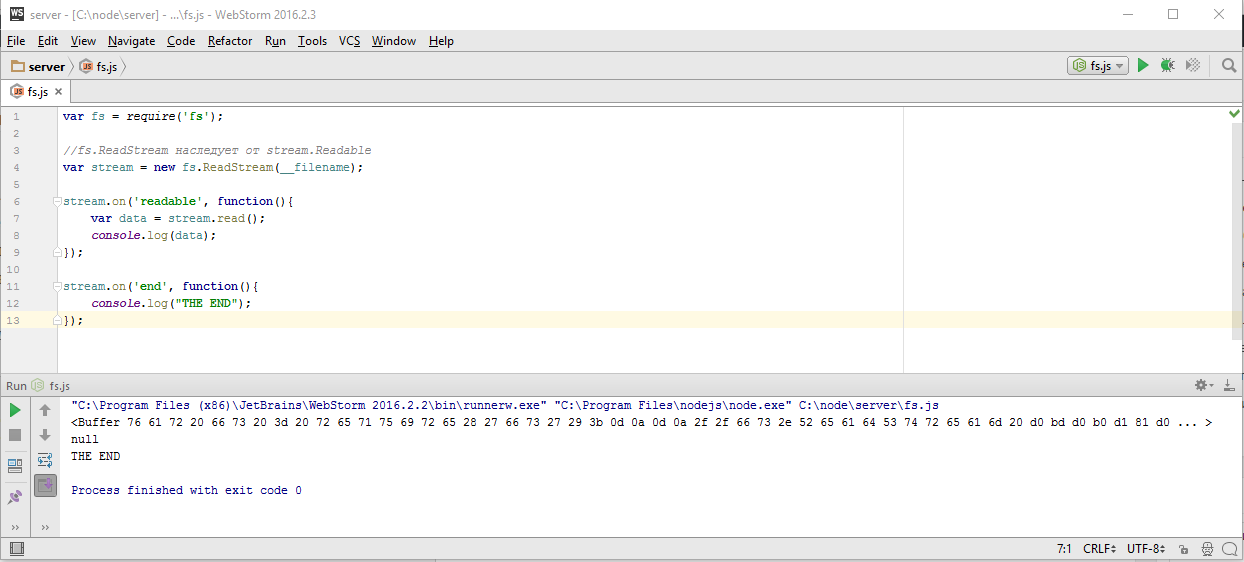
Первое сработало событие ‘readable’ и оно вывело данные, сейчас это обычный буфер, но я могу преобразовать его к строке используя кодировку utf-8 обычным вызовом toString
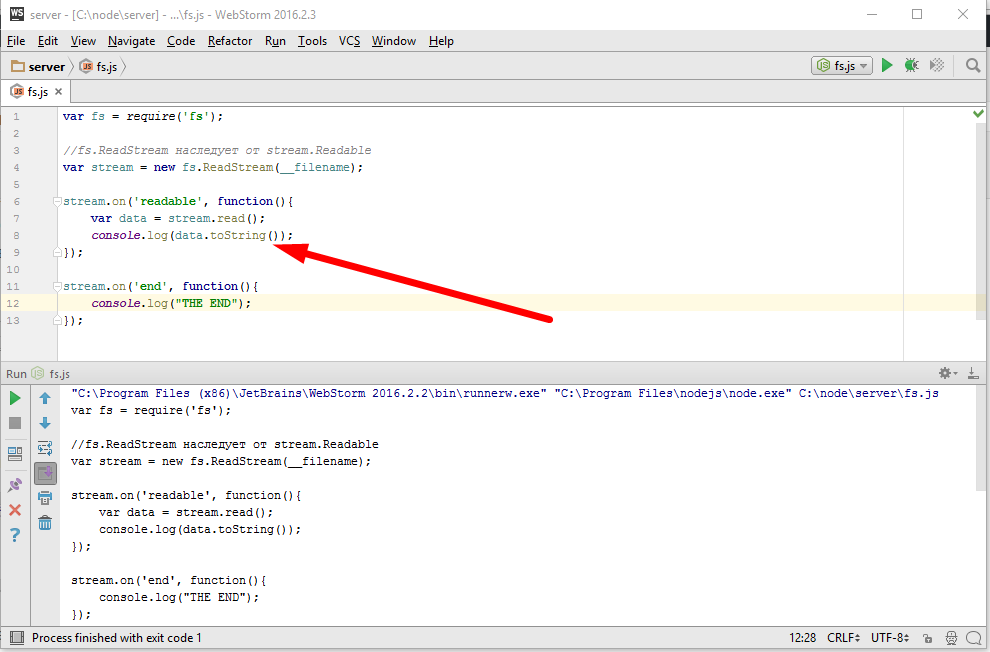
Еще один вариант, указать кодировку непосредственно при открытии потока
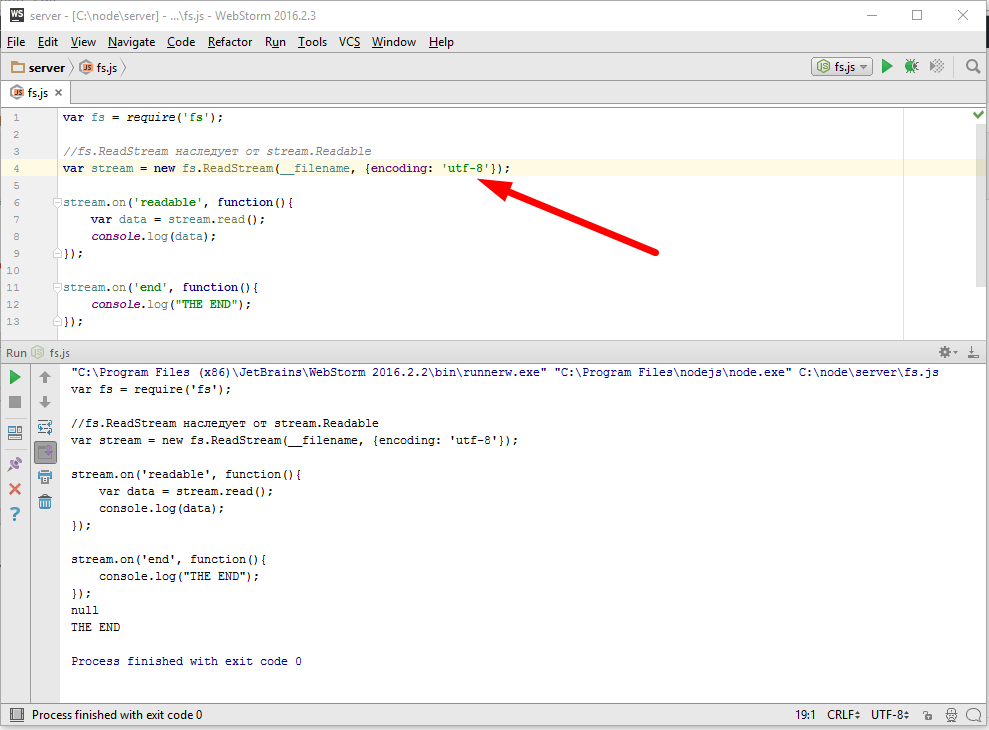
тогда преобразование будет автоматическим и toString() нам не нужен.
Наконец когда файл закончился,
|
10 11 12 13 |
stream.on('end', function(){ console.log("THE END"); }); |
то событие ‘end’ вывело мне в консоль «THE END». Здесь фай закончился почти сразу, поскольку он был очень маленький. Сейчас я не много модифицирую пример, сделаю вместо «__filename», то есть вместо текущего файла, файл «big.html», который в текущей директории находится.
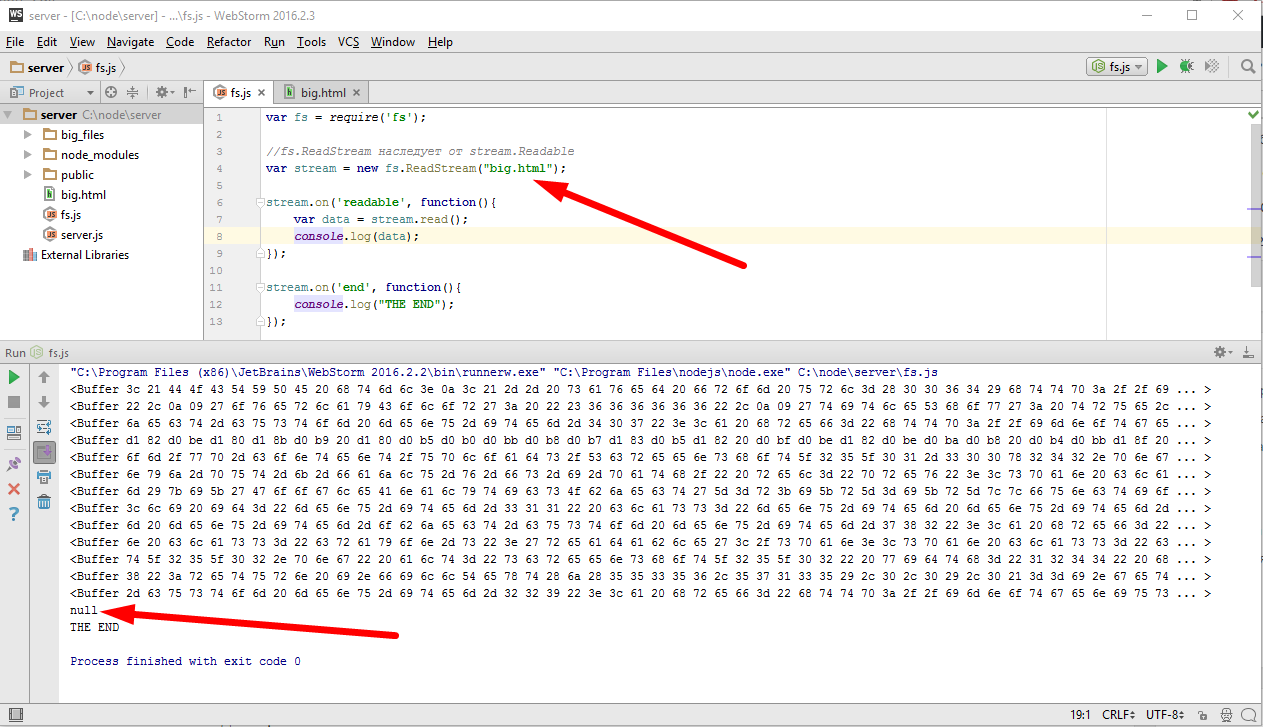
Файл big.html большой, по этому событие readable срабатывало многократно и каждый раз мы получали очередной фрагмент данных в виде буфера. Так же обратите внимание на вывод null который нас постоянно преследует, о причине этого вывода вы можете прочесть в документации, там сказано, что после того как данные заканчиваются readable возвращает null. Возвращаясь к нашему буферу, давайте я выведу в консоль его размер и заодно сделаю проверку на но то чтоб вывод был не null
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var fs = require('fs'); //fs.ReadStream наследует от stream.Readable var stream = new fs.ReadStream("big.html"); stream.on('readable', function(){ var data = stream.read(); if(data != null)console.log(data.length); }); stream.on('end', function(){ console.log("THE END"); }); |
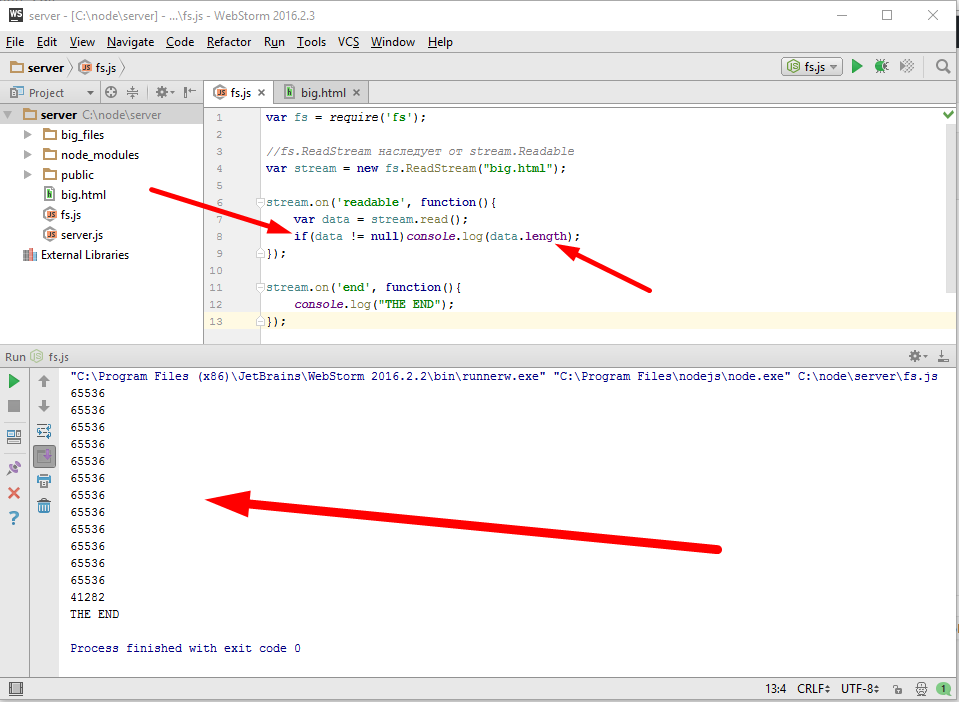
Эти числа, не что иное как длина прочитанного фрагмента файла, потому что поток когда открывает файл, он читает из него не весь файл конечно же, а только кусок и помещает его в свою внутреннюю переменную и максимальный размер, это как раз шестьдесят четыре килобайта. Пока мы не вызовем stream.read(), он дальше читать не будет. После того как я получил очередные данные, то внутренний буфер очищается и он может еще фрагмент прочитать, и так далее и так далее, последний фрагмент имеет длину остатка данных. На этом примере мы отлично видим важное преимущество использования потоков, они экономят память, какой бы большой файл не был, все равно, единовременно мы обрабатываем вот такой небольшой фрагмент. Второе, менее очевидное преимущество, это универсальность интерфейса. Здесь
|
4 |
var stream = new fs.ReadStream("big.html"); |
мы используем поток ReadStream из файла, но мы можем в любой момент заменить его на вообще произвольный поток из нашего ресурса, это не потребует изменения оставшейся части кода
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var fs = require('fs'); var stream = new OurStream("our resourse"); stream.on('readable', function(){ var data = stream.read(); if(data != null)console.log(data.length); }); stream.on('end', function(){ console.log("THE END"); }); |
Потому что потоки это в первую очередь интерфейс, то есть в теории, если наш поток реализует необходимые события и методы, в частности наследует от stream.Readable, то все должно работать хорошо, но это конечно же только в том случае если мы не использовали специальных возможностей, которые есть у файловых потоков. В частности у потока ReadStream есть дополнительные события
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var fs = require('fs'); //fs.ReadStream наследует от stream.Readable var stream = new fs.ReadStream("big.html"); stream.on('readable', function(){ var data = stream.read(); if(data != null)console.log(data.length); }); stream.on('end', function(){ console.log("THE END"); }); |
Здесь изображена схема именно для fs.ReadStram и новые события изображены красным
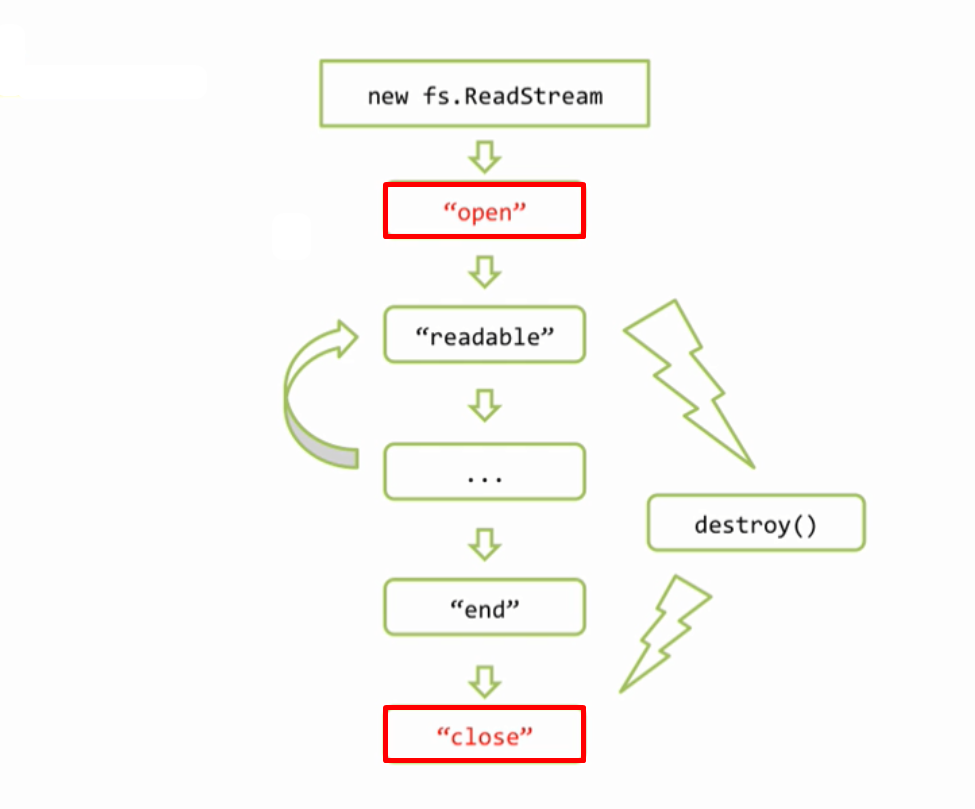
Вначале это открытие файла, а в конце закрытие. Обратим внимание, что если файл полностью дочитан, то возникает событие «end» затем «close», а если файл не дочитан, например из за ошибки или при вызове метода destroy(), то «end» не будет, поскольку файл не закончился, но всегда гарантируется, при закрытии файла, событие «close».
И наконец, последняя по коду, но не последняя по важности деталь, обработка ошибок. Например посмотрим что будет если файла нет
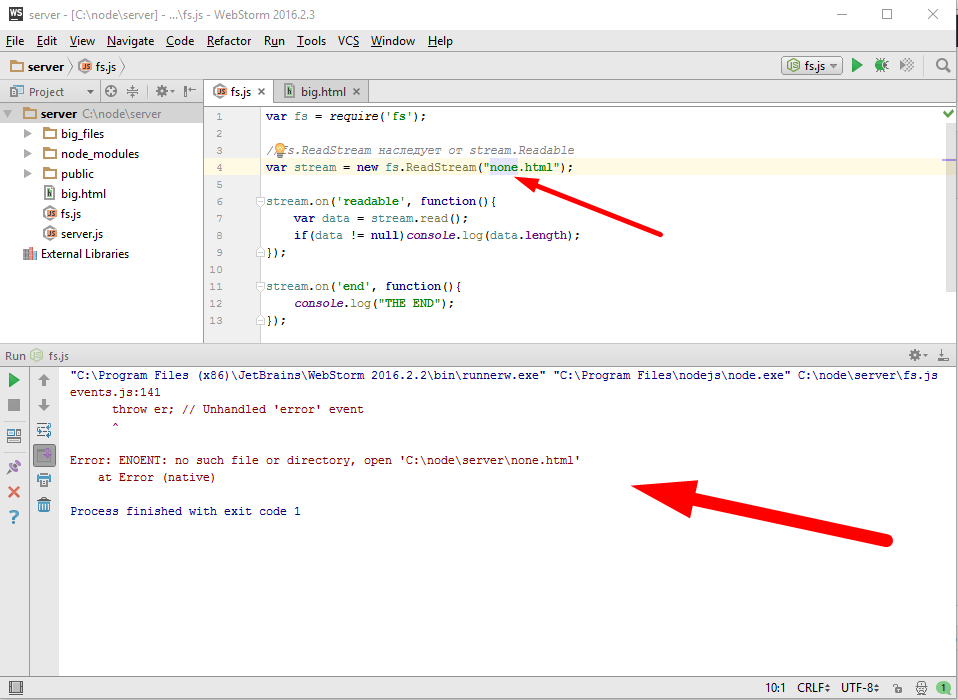
упс, все упало. Обратите внимание, потоки наследуют от event EventEmitter, про него была глава, если происходит ошибка, то весь процесс node.js падает. Это в том случае конечно, если на эту ошибку нет обработчиков, по этому если мы хотим, чтоб Node.JS вообще не упал, то нужно обязательно обработчик поставить
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
var fs = require('fs'); //fs.ReadStream наследует от stream.Readable var stream = new fs.ReadStream("none.html"); stream.on('readable', function(){ var data = stream.read(); if(data != null)console.log(data.length); }); stream.on('end', function(){ console.log("THE END"); }); stream.on('error', function(err){ if(err.code == 'ENOENT'){ console.log("Файл не найден"); }else{ console.error(err); } }); |
Итак, для работы с источниками данных в Node.JS используются потоки, здесь мы рассмотрели общую схему по которой они работают
и ее конкретную реализацию, а именно fs.ReadStrem
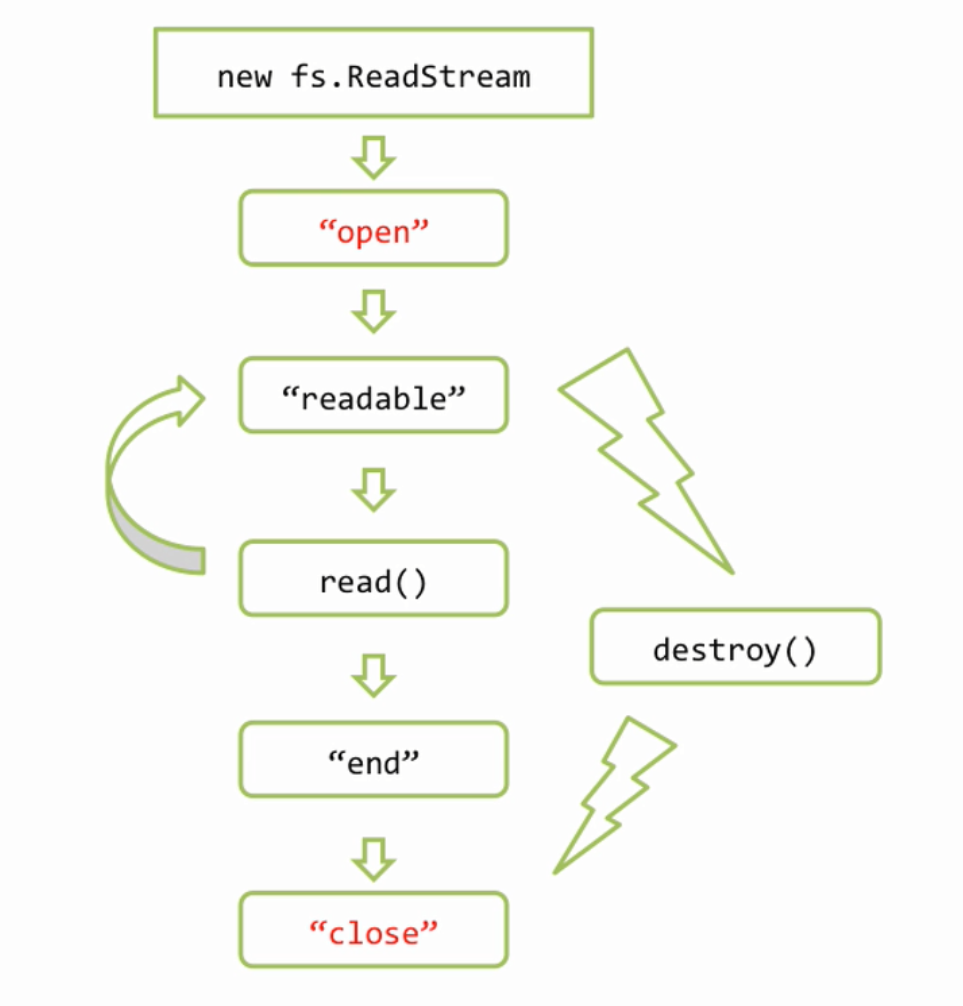
которая умеет читать из файла.
Невероятный сайт! Спасибо что вы есть! Никогда бы не освоил JS без этого блога. Автор понимает что нужно людям: обьяснить людям глубокие и непростые темы понятным языком при помощи схем и примеров из кода, а главное: С ПОДРОБНЫМ ОБЪЯСНЕНИЯМ К НИМ.
Спасибо еще раз!
Круто объяснили!
Спасибо! Отличный материал.