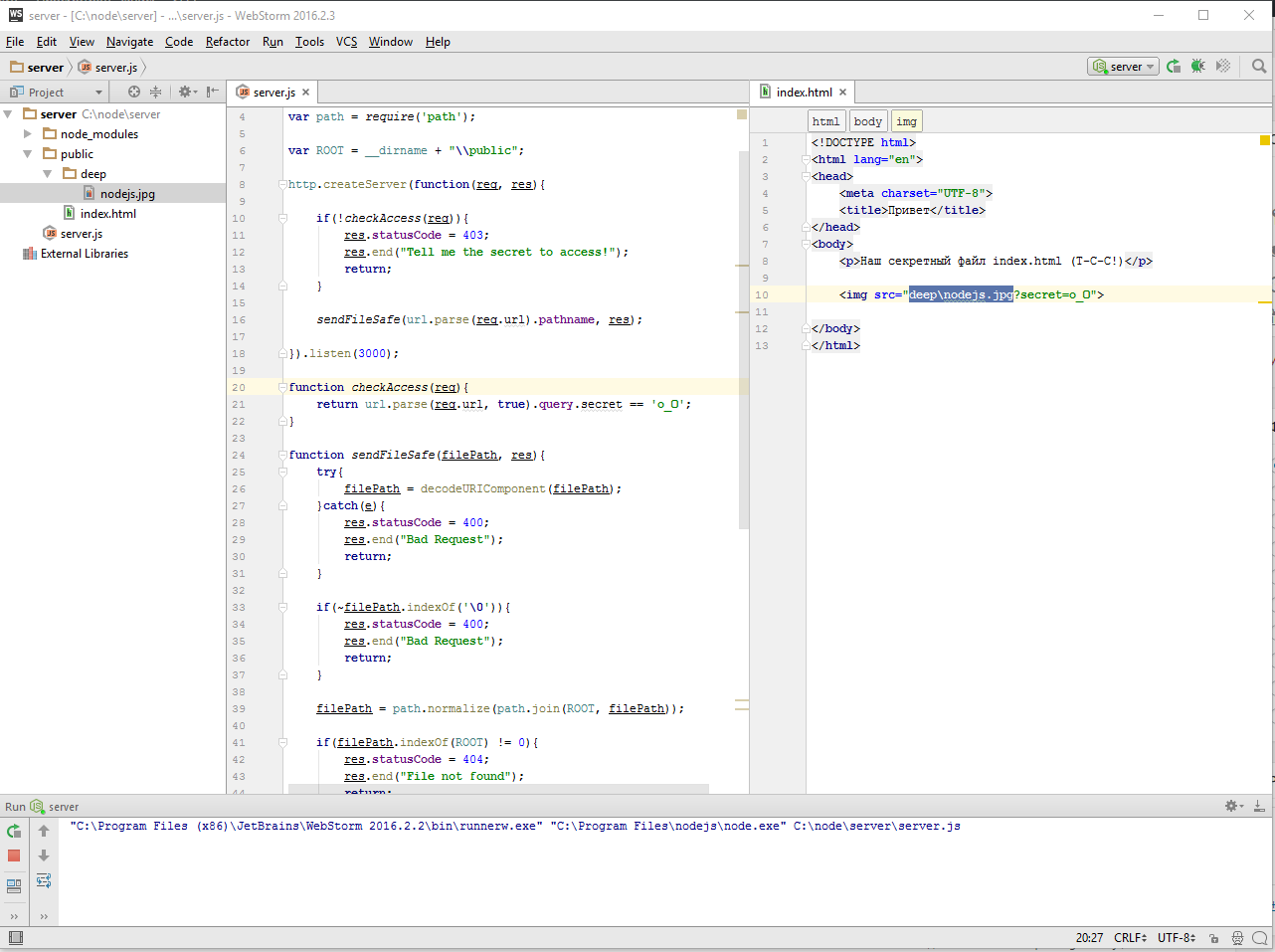
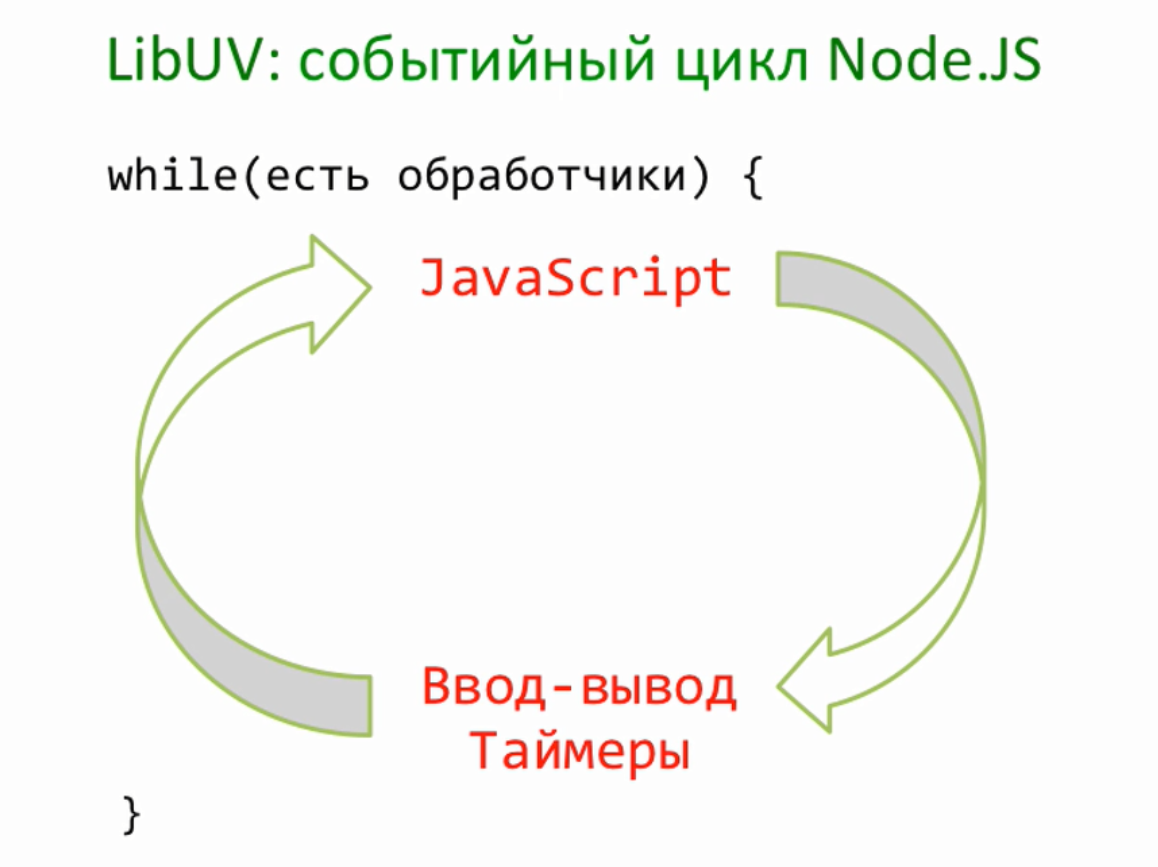
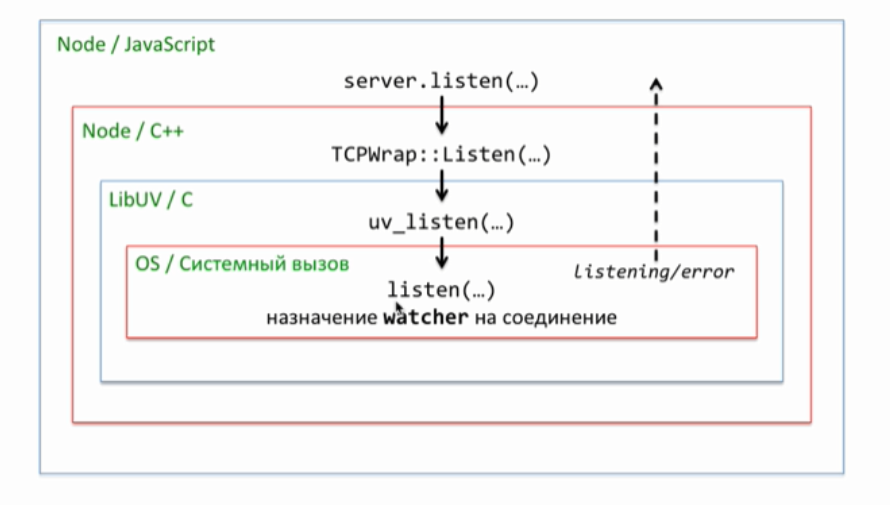
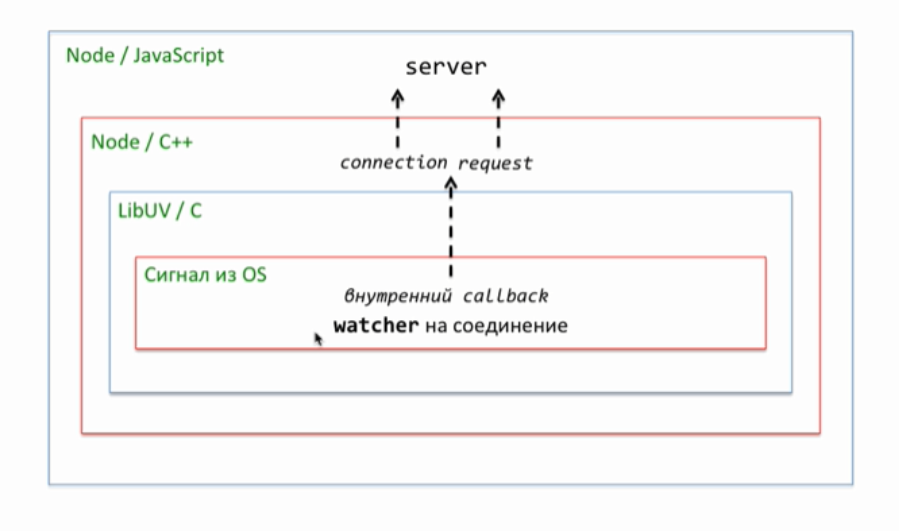
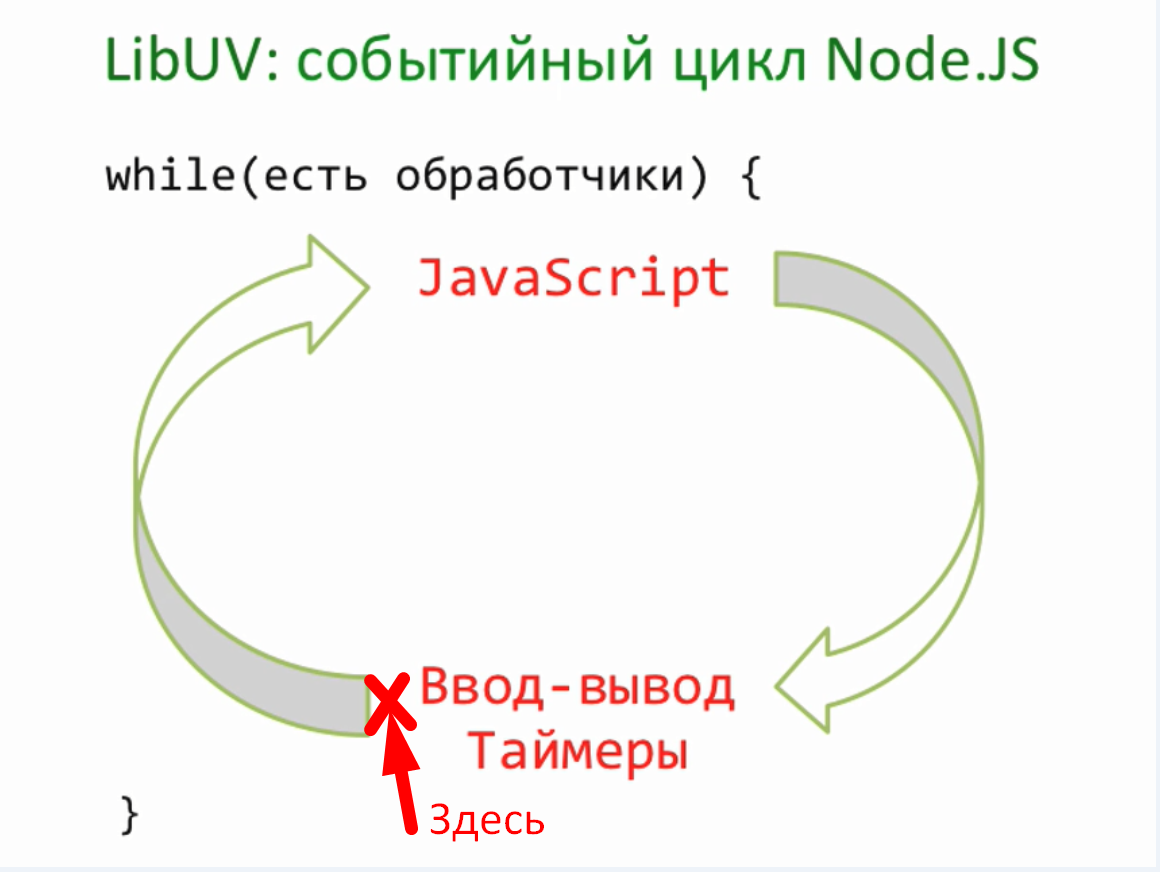
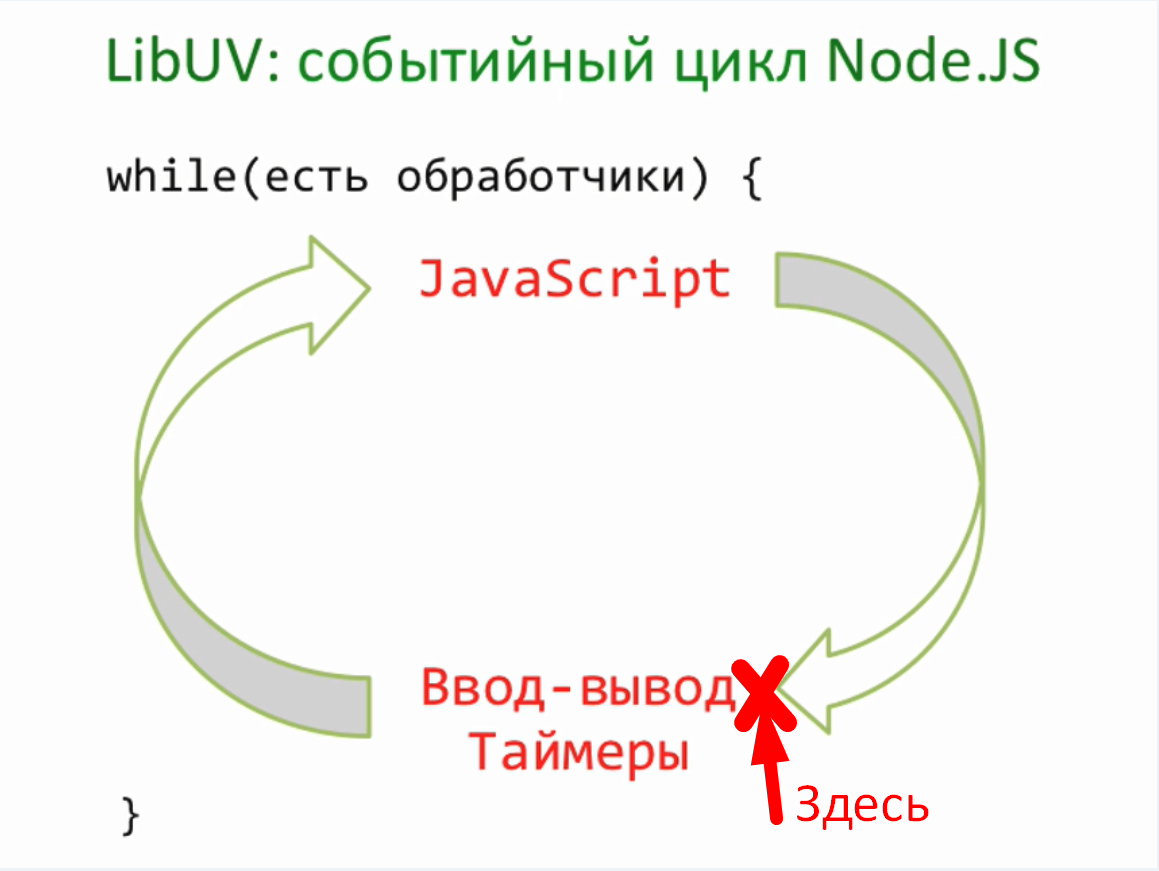
Наша следующая тема логирование или иначе говоря отладочный вывод. Когда проект маленький, то вполне достаточно console.log для того, чтобы что-то вывести. Однако проект имеет свойство расти. Например, тот же server.js естественным образом разделяется на сервер и обработчик запроса — request. Со временем появляется работа с пользователем, база данных и так далее. Каждый файл может захотеть по ходу своего выполнения, что-то вывести. И этот вывод для нас очень важен, поскольку показывает, что происходит. Особенно, если что-то происходить не так. В текущем коде, везде используется console.log для вывода
|
|
var http = require('http'); var server = http.createServer(); server.on('request', requre('./request')); server.listen(1337); console.log("Server is running"); |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
var url = require('url'); module.exports = function(req, res) { var urlParsed = url.parse(req.url, true); console.log("Got request", req.method, req.url); if(req.method == 'GET' && urlParsed.pathname == '/echo' && urlParsed.query.message){ var message = urlParsed.query.message; console.log("Echo: " + message); res.end(message); return; } console.log("Unknown URL"); res.statusCode = 404; res.end('Not Found'); } |
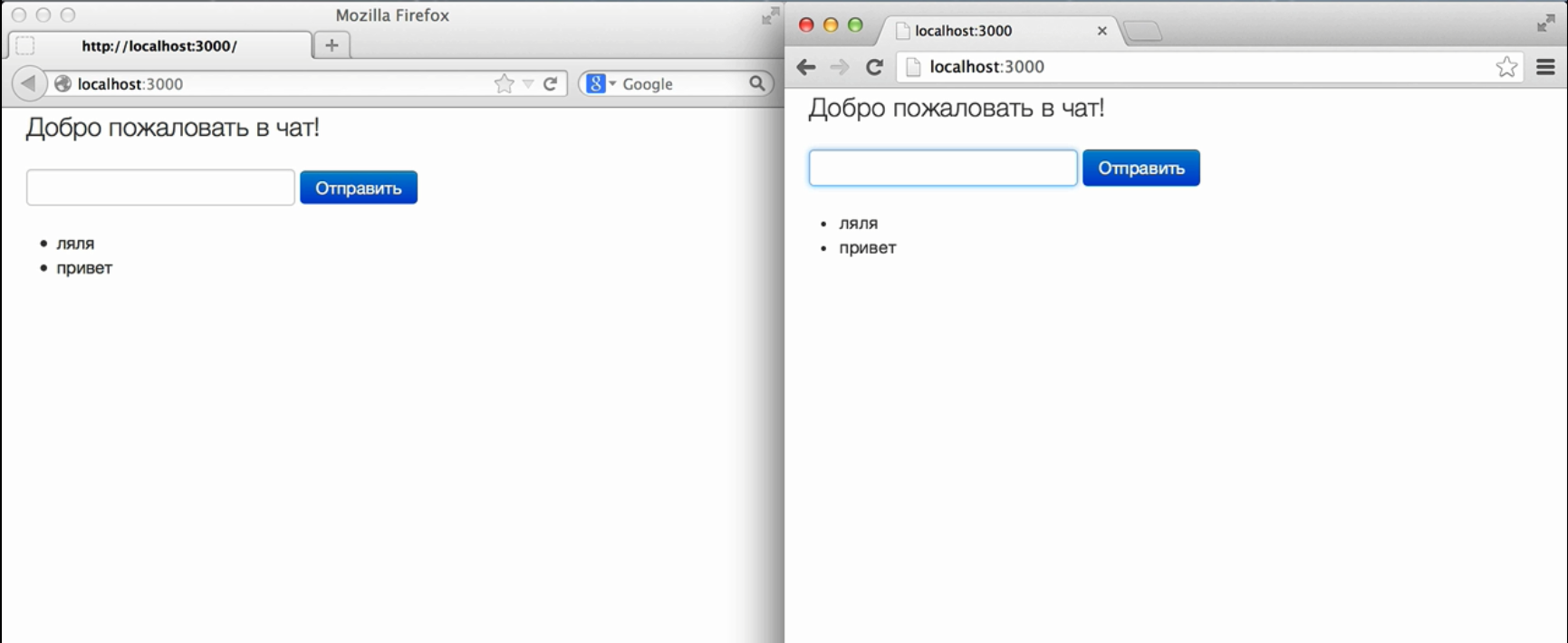
Это означает, что перейдя по браузерному url, я получу однообразную кашу из всех записей, что делает скрипт.
|
|
Server is running Got request GET /echo?message=TEST Echo: TEST Got request GET /favicon.ico Unknown URL |
Какая из этих записей сделана каким модулем, совершенно не понятно. Иногда конечно можно примерно сообразить, но вообще говоря не очевидно. А по мере появления новых модулей, будет менее очевидно, логи будут расти, соответственно найти то что нас интересует будет все сложнее. Кроме того нужен какой то способ включить вывод только в определенных файлах, в тех, которые нас в данный момент интересуют, в которых могут быть ошибки, которые мы сейчас разрабатываем.
Для этого используются специализированные модули. Рекордсмен по простоте, это модуль DEBUG.
Модуль debug
Давайте поставим его в наш проект. Для этого вспоминаем главу — 7. Введение в NPM — менеджер пакетов для Node.JS и в консоле, из директории проекта, вводим команду
|
|
C:\node\server>npm install debug |
получаем
как видим NPM создал, как в общем то и ожидалось, директорию «node_modules» в корне нашего проекта
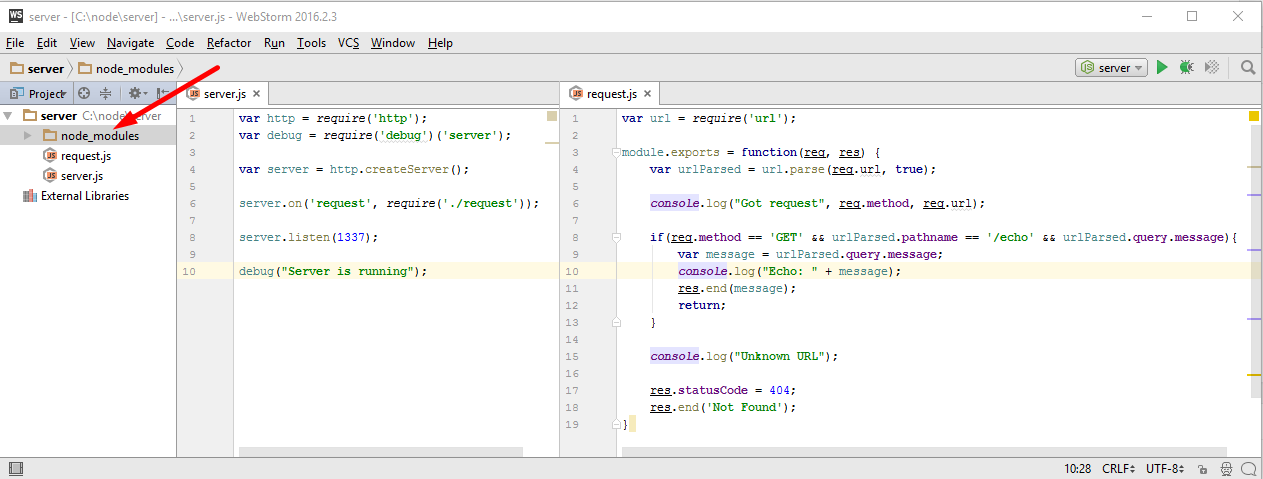
куда и поставил новый модуль, «debug». Давайте теперь подключим его, добавив такую строку
|
|
var debug = require('debug'); |
но этого мало, при подключении нужно указать идентификатор, которым он будет метить весь вывод из данного файла
|
|
var debug = require('debug')('server'); |
Вот так, в данном случае, пусть это буде ‘server’. Теперь вместо console.log мы пишем debug
|
|
var http = require('http'); var debug = require('debug')('server'); var server = http.createServer(); server.on('request', require('./request')); server.listen(1337); debug("Server is running"); |
Аналогичную операцию я произвожу и с файлом request.js, только на этот раз идентификатором будет не ‘server’ a ‘server:request’. Обратим внимание на двоеточие в ‘server:request’, это нам еще будет важно
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
var url = require('url'); var debug = require('debug')('server:request'); module.exports = function(req, res) { var urlParsed = url.parse(req.url, true); debug("Got request", req.method, req.url); if(req.method == 'GET' && urlParsed.pathname == '/echo' && urlParsed.query.message){ var message = urlParsed.query.message; debug("Echo: " + message); res.end(message); return; } debug("Unknown URL"); res.statusCode = 404; res.end('Not Found'); } |
Итак, запускаю, сейчас не из WebStorm а через терминал
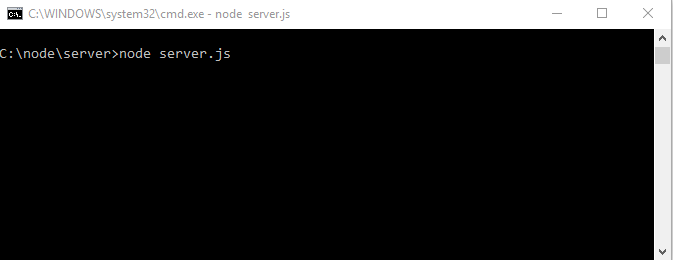
И мы видим, что ничего не выводит, потому что, чтоб выводило, мне нужно указать, что выводить. Для возврата в исходный режим нажимаем сочетание клавиш «Ctrl + C». И пробуем еще раз, но теперь для передачи информации о том, что выводить, нужно создать переменную окружения с названием «DEBUG» и дать ей значение, для начала, «server»
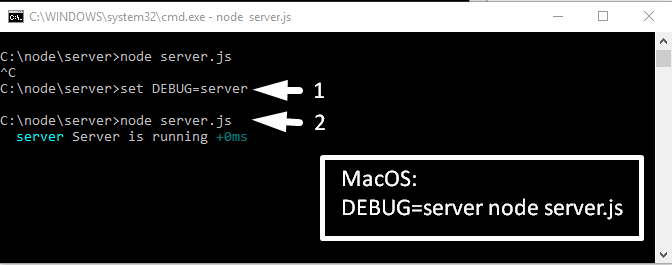
На эту тему, для пользователей windows, есть интересная статья —
Что произошло? Мы создали переменную которой дали значение, запустили сервер и видим что в консоль дебагом выведено сообщение которое помечено идентификатором «server».
У нас ведь есть еще один файл, который тоже должен выводить, нужную нам, информацию в консоль. Но в фале request.js другой идентификатор, а именно — ‘server:request’, давайте добавим его в нашу переменную. Вводим в консоле
|
|
C:\node\server>set DEBUG=server:request,%DEBUG% |
Давайте чуть отвлечемся и проговорим вот такой момент, который сейчас важен. Переменная «DEBUG» имеет значение, это мы уже поняли. Это значение это строка. И если до последней команды в консоле, эта строка была равна «DEBUG=server», то после она стала равной «DEBUG=server:request,server». Как видим последней командой мы дописали значение в начало этой строки.
От сюда делаем два вывода —
- во первых принципиально важно не забыть поставить запятую после выражения которое мы хотим добавить к нашей строке, потому что именно по запятым парсится значение переменной DEBUG, и отделяя запятыми мы перечисляем идентификаторы которыми помечены интересующие нас логи, прямо как точка с запятой — «;» в переменной «PATH».
- во вторых если у нас вдруг появится файл «user.js» и в нем мы подключим модуль «debug» которому укажем идентификатор, скажем, «user», то нам нужно будет опять проделать такую операцию
|
|
C:\node\server>set DEBUG=user,%DEBUG% |
если мы хотим выводить логи из этого файла.
К стати проверить значение переменной можно в любой момент, введя в консоле такую команду
Просто set и имя переменной, вот такая многогранная команда «set».
И так возвращаемся к нашему серверу. Мы добавили значение в переменную DEBUG
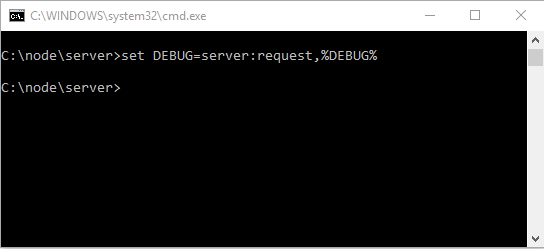
теперь посмотрим какое значение имеет переменная DEBUG
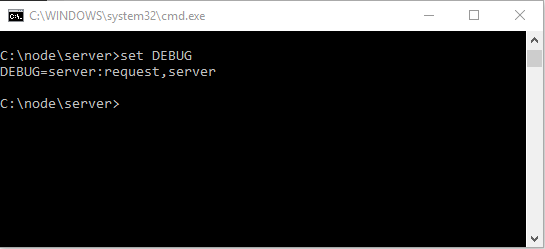
Судя по значению должно выводить логи из обоих файлов, проверим
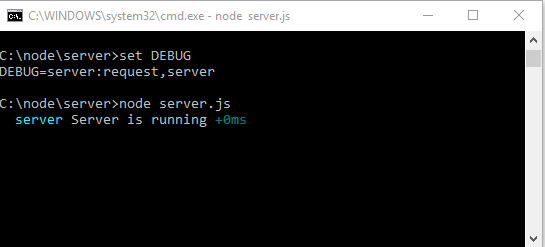
запустили сервер и он сразу вывел лог помеченный идентификатором ‘server’. Теперь перезагрузим открытую в браузере страницу по адресу — «http://127.0.0.1:1337/echo?message=TEST«, смотрим в консоль

вот и второй файл и логи в нем отработали.
К стати если мы уже решили выводить абсолютно все логи, то можно значение переменной DEBUG установить равной «*». Давайте установим, убедимся чему равно и запустим сервер. И не забываем, чтоб прервать работу сервера из консоли, достаточно нажать сочетание клавиш «Ctrl + C». Итак смотрим

Теперь перезагрузим открытую в браузере страницу по адресу — «http://127.0.0.1:1337/echo?message=TEST» и смотрим в консоль
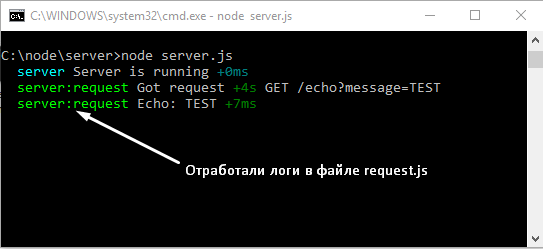
Все работает по прежнему.
Модуль winston
Модуль DEBUG это с одной стороны простое и гибкое решение задачи логгинга, с другой стороны он иногда уж слишком прост например в файле request.js у нас дебагом обозначены сообщения, важность которых совершенно различная. Скажем эта информация
|
|
debug("Got request", req.method, req.url); |
может быть средней важности при отладке. Эта информация
|
|
var message = urlParsed.query.message; debug("Echo: " + message); res.end(message); |
может быть неважной. Эта информация может быть очень важной
поскольку, это ошибка — url не найден.
При помощи DEBUG задать важность, каким то образом нельзя. Кроме того DEBUG все пишет в стандартный поток вывода, а мы можем захотеть писать в файл или базу данных. Если такая потребность возникла или планируется, что она возникнет, тогда имеет смысл взглянуть на более навороченный модуль для логирования, который называется «Winston».
Ставим его
и заменяем в коде require(‘debug’) на require(‘winston’), который возвращает объект «log».
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
var url = require('url'); var log = require('winston'); module.exports = function(req, res) { var urlParsed = url.parse(req.url, true); log.info("Got request", req.method, req.url); if(req.method == 'GET' && urlParsed.pathname == '/echo' && urlParsed.query.message){ var message = urlParsed.query.message; log.debug("Echo: " + message); res.end(message); return; } log.error("Unknown URL"); res.statusCode = 404; res.end('Not Found'); } |
Для того чтобы логировать, я должен вызвать соответствующий метод этого объекта
- log.debug — Маленькой важности
- log.info — Сообщение средней важности.
- log.error — это ошибка.
Все ошибки считаются очень важными, кроме того логгер настроен так, что по умолчанию он выводит сообщения только уровня info и более важные. Сейчас мы это увидим, запускаю в WebStorm и в браузере перехожу на соответствующий url — «http://127.0.0.1:1337/echo?message=TEST«.
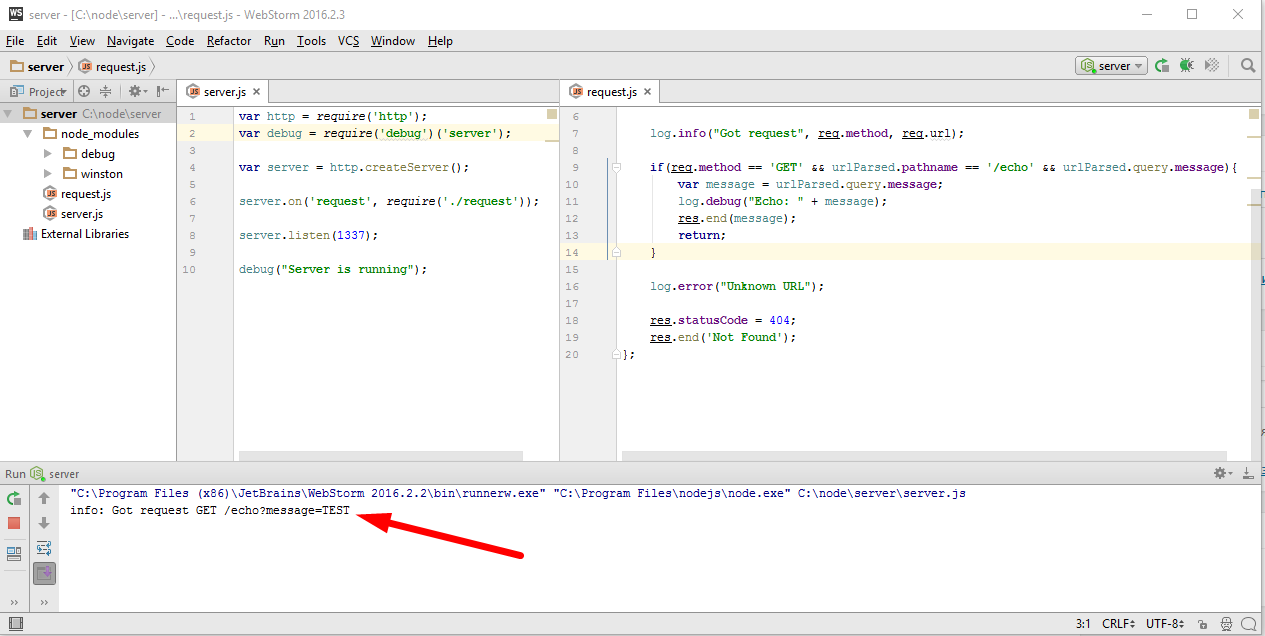
Как и говорилось ранее log.debug вообще не выводится, выводятся только сообщения уровня info и более важные, такие как error.
В модуле «DEBUG» можно было ограничить вывод, только интересующими нас модулями указав их в переменной окружения DEBUG. К сожалению в самом winston такой функциональности нету, по этому ее придется реализовать самим.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
var url = require('url'); var log = require('./log')(module); module.exports = function(req, res) { var urlParsed = url.parse(req.url, true); log.info("Got request", req.method, req.url); if(req.method == 'GET' && urlParsed.pathname == '/echo' && urlParsed.query.message){ var message = urlParsed.query.message; log.debug("Echo: " + message); res.end(message); return; } log.error("Unknown URL"); res.statusCode = 404; res.end('Not Found'); }; |
Просто сделать обертку над winston, которая будет находиться в отдельном модуле и добавлять интересующею нас функциональность. Назовем этот модуль «log», он будет принимать текущий объект модуля и возвращать по сути тот же winston, но по разному настроенный, в зависимости от того какой именно модуль мы ему передаем, для каких то будем логировать так, для каких то можно логировать по другому. Вот пример такого модуля
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
var winston = require('winston'); module.exports = function(module){ return makeLogger(module.filename); }; function makeLogger(path){ if(path.match(/request.js$/)){ var transports = [ new winston.transports.Console({ timestamp: true, //function() {return new Date().toString()} colorize: true, level: 'info' }), new winston.transports.File({ filename: 'debug.log', level: 'debug' }) ]; return new winston.Logger({ transports: transports }); }else{ return new winston.Logger({ transport: [] }); } } |
Он экспортирует функцию, которая принимает модуль для которого нужно сделать логирование и возвращает winston настроенный соответственно его пути
|
|
module.exports = function(module){ return makeLogger(module.filename); }; |
В данном случае настройка заключается в том, что мы смотрим на что заканчивается путь и если это «/request.js» то возвращаем winston настроенный одним способом
8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
if(path.match(/request.js$/)){ var transports = [ new winston.transports.Console({ timestamp: true, //function() {return new Date().toString()} colorize: true, level: 'info' }), new winston.transports.File({ filename: 'debug.log', level: 'debug' }) ]; return new winston.Logger({ transports: transports }); |
а если это что-то другое то другим
|
|
}else{ return new winston.Logger({ transport: [] }); } |
Для настройки winston здесь используется концепция транспортов. Транспорт это нечто, что умеет передавать информацию, в данном случае информацию из логов. Например есть встроенный в winston транспорт «Console»
|
|
new winston.transports.Console({ timestamp: true, //function() {return new Date().toString()} colorize: true, level: 'info' }), |
Который можно настраивать вот так, указать timestamp, расцветить — colorize, level — использовать его только для сообщений уровня info и выше.
Второй транспорт здесь это файл
|
|
new winston.transports.File({ filename: 'debug.log', level: 'debug' }) |
который записывает логи, как указано, в файл с названием ‘debug.log’ — filename: ‘debug.log’ и будет включаться для сообщений уровня debug и выше — level: ‘debug’. То есть фактически для всех. Таким образом, если путь оканчивается на /request.js, то мы возвращаем winston
|
|
return new winston.Logger({ transports: transports }); |
который будет записывать в консоль сообщения info или выше и в файл вообще все.
ну, а для других путей, мы будем возвращать winston вообще без транспортов.
|
|
return new winston.Logger({ transport: [] }); |
соответствующие вызовы log, с одной стороны не будут вызывать ошибку, а с другой стороны такая запись никуда не пойдет.
Проверяю это, запустив сервер и перейдя в браузере по адресу — «http://127.0.0.1:1337/echo?message=log-me-please» и мы видим

что действительно информация info, попала в консоль, а так же появился файл debug.log, в котором есть все, все сообщения.
Итак мы с вами рассмотрели отладку,
во первых, при помощи модуля debug, который с одной стороны весьма прост, с другой стороны позволяет указать какую ветку кода логировать, и вообще для большинства задач разработки его вполне хватает.
Но если требуется более серьезное логирование, в том числе в несколько мест одновременно, или в базу данных или в файл, тогда имеет смысл обратить внимание на другой модуль, который называется winston. Его можно гибко настраивать в том числе при помощи обертки.
NODE_DEBUG
Следующие средство отладки которое мы сейчас изучим называется NODE_DEBUG=»cluster fs http module net timer tls». NODE_DEBUG это переменная окружения которая используется внутри Node.JS. Есть ряд встроенных модулей которые, если эта переменная стоит, могут показывать, что происходит внутри них. Таким образом NODE_DEBUG, это средство для глубокой отладки. Его используют в тех случаях, когда наши возможности по отладке исчерпаны и нам ничего не остается, кроме как заглянуть внутрь самой ноды и посмотреть, что же там делается внутри.
Например, мы хотим посмотреть, что передается по сети. Для этого нужно запустить ноду, сначала установив переменную окружения
|
|
C:\node\server>set NODE_DEBUG="http net" |
на этот раз разделяем, значения присваиваемые переменной NODE_DEBUG, пробелами. И запускаем наш server.js. Для MacOs это будет выглядеть вот так
|
|
C:\node\server>NODE_DEBUG="http net" node server.js |
в этом случае, мы полностью поймем, что внутри сети здесь творится.
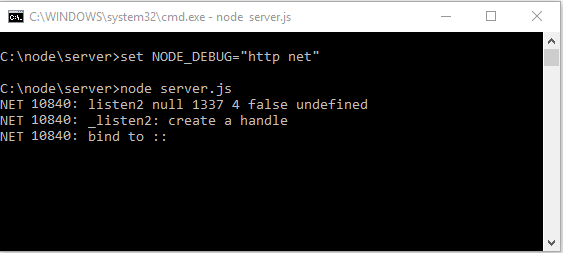
Смотрите, я только запустил, не успел никуда зайти, а уже начала поступать информация модуль NET вывел, что мы теперь слушаем все интерфейсы и порт 1337. А теперь перейду по адресу «http://127.0.0.1:1337/echo?message=TEST»
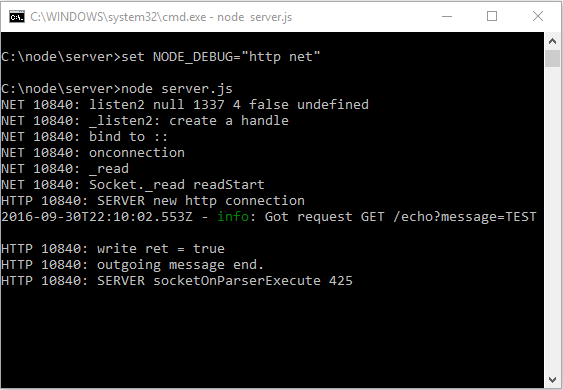
и как видите, я получаю полный отчет, о том, что происходит.
Итак, у нас есть три инструмента логирования, которых хватит как для отладки небольшого проекта, так для полноценного логгинг-решения, ну и на конец, чтобы заглянуть внутрь Node.JS.